

1. What Is FinOps?
A practice, a process, a hub; a central body dissolving barriers between different realms of an organization. The fabled combination of engineering and finance teams. The taming of that resource which no digital-native business can survive without: the cloud. FinOps is a many-splendored thing.
FinOps is the practice of maximizing the ROI of your cloud investment.
FinOps’s roots go back to roughly 2012, and it gathered serious momentum toward the end of the 2010s, as cloud usage rose exponentially. It takes cues largely from DevOps, another engineering-oriented discipline that seeks to optimize the development, release, and iteration of digital applications.
Broad organizational uptake of FinOps was marked by the 2019 founding of the FinOps Foundation, now a division of the Linux Foundation.
As defined by its namesake foundation: “FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping engineering, finance, technology and business teams to collaborate on data-driven spending decisions.”
What Does That Mean?
- Maximizing the ROI of your cloud investment. Executives estimate that around30% of their cloud spend is wasted. FinOps seeks to turn every dollar you spend on the cloud into actual business value.
- Giving different teams a shared language in which to understand and discuss cloud usage. While FinOps primarily centers on aligning engineering and finance teams (the former responsible for building cloud infrastructure, the latter paying for it), the platonic version of FinOps applies to every team in an organization.
Given that each team has a different area of expertise, each one has a different lexicon in which they process their work. This produces natural misalignments and gaps in understanding which FinOps fills. - Make sure every cloud user in an organization owns and is accountable for their cloud usage. It used to be that a centralized procurement team would review and approve every IT infrastructure purchase. That’s not how it works anymore. Now, IT infrastructure spending is largely decentralized, with purchasing power resting in the hands of everyone who uses the cloud. FinOps makes every cloud user responsible for their cloud usage.
What Does That Not Mean?
- Minimizing your cloud spend. A common misconception is that FinOps means spending as little on the cloud as possible. FinOps means spending as little as possible to get the most possible value. It’s an important difference — FinOps aims to quantify the value you get from your cloud spend, not track cloud spend trends in isolation.
- Only optimizing your cloud spend. Some people conflate “FinOps” and “optimization.” While it’s true that rate optimization — through tools like Reserved Instances (RIs) and Savings Plans (SPs), which all cloud providers offer — is a core domain of FinOps, it’s only one part of a much broader practice.
FinOps is a multifaceted, multidisciplinary process that, in its ideal form, extends to every dimension of your organization. It’s a way for different experts to collaborate over a common, urgent goal: turning cloud spend from an unpredictable liability into a manageable asset.
2. Why Does FinOps Matter?
FinOps is a paradigm and practice aimed at maximizing the ROI of your cloud investment. What makes FinOps so urgent? Why does it deserve its own dedicated practice?
FinOps matters because of how powerful the cloud is. Resources like public cloud platforms (AWS, Azure, GCP) combined with specialized cloud tools (Snowflake, MongoDB, Kubernetes) have unlocked undreamed-of business potential.
But with that business potential comes a great deal of risk (Spiderman’s uncle might know how to sum this up). The digitizing of IT infrastructure blew open the doors for light-speed innovation — and uncontrollable cloud bills.
The Vicious Cycle Of Cloud Innovation
Let’s get digital
Before the cloud, if engineering teams wanted to add more compute or storage power, they had to submit a request for additional servers to a procurement team. The procurement team would evaluate the request, and if they approved it, it would take some time for the servers to ship and get configured.
Only after this process (which could take weeks) could engineering get the new servers up and running and delivering value.
The cloud dismantled this procurement process. Physical servers were replaced by cloud-based virtual servers — “instances” — which just took some engineering know-how to buy and implement. Now, instead of a lengthy request, approval, shipping, and configuration process, engineers could simply spin up as many virtual servers as they needed.
More sophisticated solutions like Kubernetes further enhanced this process, allowing companies to grow or shrink their IT infrastructure according to user demand.
For example, when Spotify listeners fire up the streaming service at 4:00 p.m. (peak listening hours), Spotify can spin up new servers to process that demand, then code them out of existence when activity dies down a couple hours later. It would be like building and demolishing a data center every day, at flexible specifications depending on moment-to-moment demand.
This unprecedented flexibility eliminated a major scaling obstacle for digital-native businesses. Whereas before, business growth depended on the speed at which organizations could request, approve, acquire, and configure new physical servers, now, business growth could now happen as fast as engineers could spin up new instances.
The bill comes due
Throughout the 2010s, we saw organizations spare no expense to exploit these new capabilities and scale as fast as possible.
The cloud went from a competitive advantage to a competitive necessity, and as it did, cloud spending skyrocketed. In 2010, the global cloud computing market was valued at $24.63 billion, and by 2020, it had grown to $156.4 billion (a 635% increase).
The other factor in this equation was a philosophical one. Throughout the 2010s, the business metric valued above all others was “top-line revenue growth” — how much a company’s revenues grew over time.
Importantly, this metric omits how much it cost to get that revenue; businesses (and investors) generally felt that sufficient growth could justify any costs.
But by the early 2020s, the obvious flaws in this philosophy reared their heads.
Cost-inefficient innovation may work when markets are on a 129-month winning streak, but when markets falter (which they always do eventually), businesses feel existential pressure to cut costs. Efficient innovation metrics replaced top-line revenue growth as the philosophical North Star, and businesses needed tools to adjust course.
And yep, you guessed it: Cloud costs have fallen squarely into the cost-efficiency crosshairs.
The cloud is as necessary as ever, but businesses can’t afford to keep spending inefficiently on it. Now more than ever, they need to be certain that the dollars they invest in the cloud are producing actual value.
Hence, FinOps
In sum: FinOps exists because of:
- How quickly cloud spend has accelerated and will keep accelerating if unchecked;
- How much of it is wasted (usuallyestimated at about 30%); and
- How necessary the cloud is, and will remain, to modern business.
In 2023, Gartner estimates that organizations will spend nearly $600 billion on the cloud. Other research indicates this number will exceed $1 trillion by 2028, and take only another two years after that to exceed $1.6 trillion.
The cloud is the engine of modern business. FinOps is about making that engine as fuel-efficient as possible (a metaphor our CEO, Phil Pergola, explored in this article).
3. Who’s In Charge Of FinOps (And What Do They Actually Do)?
FinOps is still a very new paradigm, and so organizations take a variety of approaches to personnel. Some useful info from the FinOps Foundation’s State of FinOps 2022 report:
- The average FinOps team size is five people
- The organizations newest to FinOps have the smallest teams (average of three people); the most mature FinOps operations have the largest teams (average of nine)
- All FinOps team sizes will grow from 50-60% in the next 12 months
- Common FinOps team members/titles include:
- Cloud Architects
- CPAs and other finance professionals
- Capacity Planners/Forecasting Specialists
- FinOps Evangelists (yes, really)
- Data Analysts
- Technical Writers/Communicators
As you can see, FinOps teams collate a range of expertise, from engineering to finance to strategy and communication.
This is because FinOps impacts every sphere of an organization, and so FinOps teams must be able to understand the needs and communicate in the language of all stakeholders.
FinOps is a developing practice that manifests differently in different types of organizations. Thus, there’s no one-size-fits-all approach to assembling a FinOps team. But whether your team consists of architects, evangelists, bookkeepers and/or scribes, there are some universal goals that they should use as North Stars.
Universal FinOps Team Goals
1. Align people with different specialties over common goals
The most common expertise gap that FinOps seeks to bridge is that between engineering and finance teams. Engineering’s main goal is to build great products; finance’s main goal is to maximize cost-efficiency.
In the cloud age, these two goals have natural frictions. Building great products often means leveraging the most sophisticated cloud resources, which is expensive. Maximizing cost-efficiency may mean restricting resources and hampering product quality.
FinOps combines these two goals, aligning the two teams over the common objective of great, cost-efficient products. FinOps gives engineers meaningful, easily digestible cost data, and gives finance a richer picture of the context behind cost fluctuations that might otherwise look scary.
But FinOps isn’t just about finance and engineering. As more meaningful cost data comes in, strategy professionals can use it to identify the most fruitful opportunity areas. Marketing professionals can use it to better understand customer usage habits and tailor messaging accordingly.
Cost-efficiency in the cloud — and the data-richness that results — impacts every realm of an organization.
2. Establish a common language in which to discuss and evaluate those goals
Each specialty area has its own lexicon. Stepping out of your specialty area and into another is therefore like visiting a foreign country where you’re only semi-familiar with the language. If you’ve ever tried to read an article on some highly nuanced scientific achievement, you know what this feels like.
FinOps acts as a translator between people with very different areas of expertise. Financiers will never understand every aspect of Kubernetes (nor should they); engineers will never understand every aspect of free cash flow margin (nor should they).
But where their jobs relate to the same strategic goals, they should be able to communicate with each other easily enough to meaningfully assess their status relative to those goals.
Examples of common language include metrics that are mutually useful and digestible to both teams, especially unit costs like cost per customer, cost per application, cost per product feature, cost per team, etc.
3. Handle rate optimization
There’s an ongoing debate about what FinOps functions should be centralized vs. decentralized — i.e.: the responsibility of the central FinOps team vs. the responsibility of each cloud user.
But at the time of writing, the FinOps Foundation clearly recommends that central FinOps teams should handle rate optimization: maximizing the discounts they get from cloud providers.
Common discount instruments include Reserved Instances (RIs, which come in multiple flavors) and Savings Plans (SPs). The FinOps team should be responsible for collecting usage data and using it to inform purchasing decisions.
(CloudZero partnered with ProsperOps, whose AI-driven algorithms autonomously build “portfolios” of discount instruments according to past usage and forecasts. Users can integrate ProsperOps data with CloudZero’s platform to get a rich picture of optimization, unit costs, and more.)
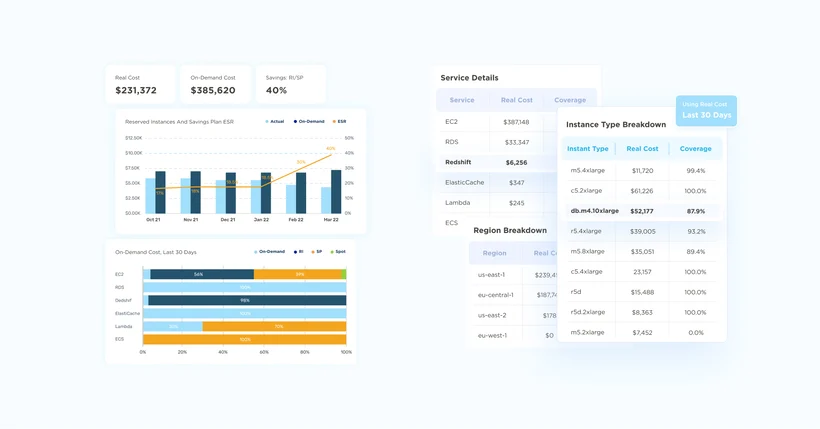
4. Foster a culture of cloud cost-consciousness
The overarching goal of FinOps is to create a culture in which cloud cost-consciousness is a given. Engineers consider cost as they build cloud-native infrastructure, financiers understand cloud cost trends in a business context, and everyone shares the goal of maximizing the ROI of the organization’s cloud investment.
The goals of FinOps are a lot like the global goal of energy consciousness.
If everyone in the world understood the consequences of energy inefficiency and took steps to be more responsible energy consumers, it would have a dramatic positive impact on the health of the human species.
It starts with a paradigm, it manifests in meaningful data, and it gets emphasized in feedback and iteration. The FinOps team is the one responsible for precipitating this change and sustaining it over time.
4. Key FinOps Frameworks And Tradeoffs
Getting a FinOps practice off the ground isn’t easy. It requires buy-in from all levels and realms of an organization, and higher-order objectives like forecasting cloud spend at sub-5% variance won’t happen overnight.
But you know what they say: Rome wasn’t architected in a day. Or something like that.
As such, the FinOps Foundation has established some universal frameworks to help orient organizations looking to establish a FinOps practice. Whatever your organization’s level of FinOps maturity, these will be useful guides as you look ahead to bigger, better, more dynamically allocated things.
Crawl, Walk, Run
Crawl, Walk, and Run are the three general stages of FinOps maturity. They’re similar in essence to the What About Bob? “Baby steps” framework: Start small, get some early wins, parlay many micro-achievements into macro-scale FinOps adoption.
There are no official boundary lines between the Crawl, Walk, and Run stages. But there are some common attributes associated with each:
Crawl
The “Crawl” stage is the earliest stage of FinOps implementation. Here, key stakeholders understand the value and goals of FinOps, and have established its most rudimentary tools.
- Reporting and Tooling: Limited, balance of manual and automated
- Spend allocation: Sub-50%
- Adoption level: Some major teams, but not all
- Goals: Address “low-hanging fruit,” reach 50% spend allocation, reach 20% budget variance
Walk
By the “Walk” stage, the organization has widely accepted FinOps as a driving goal and has made meaningful steps toward realizing it. They have adopted tools to automate key processes, begun to gather meaning cost data, and are beginning to convert data insights into business strategy.
- Reporting and tooling: Established, automating many FinOps Capabilities (e.g.: spend allocation, data ingestion, unit cost measurement, commitment-based discount management)
- Spend allocation: 50%+
- Adoption level: Near-universal
- Goals: Reach 80% spend allocation, reach 15% budget variance
Run
The “Run” stage is FinOps Valhalla: Cloud spend has been utterly demystified, and cost data has turned from a liability into an asset. The organization has universal FinOps understanding and uptake, near-total cost allocation, cloud unit cost data that regularly contributes to strategic business decisions.
- Reporting and tooling: Sophisticated, streamlined
- Spend allocation: 80%-90%
- Adoption level: Universal
- Goals: Exceed 90% spend allocation, reach 12% budget variance
Iron Triangle
Quality vs. time vs. cost
The Iron Triangle, also referred to as the Project Triangle, depicts the central tradeoffs of any project, and the particularly severe impacts for FinOps. Optimizing for one corner of the triangle demands concessions from other two; striking the right balance between each is a guiding objective for FinOps practices.
A prime example is manual vs. automated cloud spend analysis. Organizations that don’t have anomaly alerting tools may spend less money (in the moment), but spend lots of time tracking down the sources of cost spikes, only to provide fair-quality explanations of why the cost spike happened.
Whereas, investing in a tool that offers anomaly detection will require a capital investment, but it will eliminate time spent on anomaly investigation and enable high-quality understandings of why cost spikes happen. (This is one of CloudZero’s most popular capabilities)
Or, consider the default tradeoff teams made throughout the 2010s: Quality matters above all else — especially cost. No matter how high organizations’ cloud bills, it was worth it so long as it spurred top-line revenue growth. This produced a lot of costly, unwieldy infrastructure that became especially problematic when markets finally faltered. Now, organizations face renewed pressure to reincorporate cost into their cloud building decisions.
Whatever your level of FinOps maturity, you’ll always be making tradeoffs between Quality, Time, and Cost. But the more advanced your practice, the less dramatic, more informed, and more business-relevant the tradeoffs will become.
Inform → Optimize → Operate
Inform → Optimize → Operate is the iterative process by which FinOps practices evolve. The process doesn’t happen just once; it’s an ongoing cycle, repeatable at every stage of FinOps maturity, resulting in more valuable information and more streamlined processes.
Inform
The goal of the Inform stage is to enhance cloud cost visibility and allocation. Understand how much you’re spending and what you’re spending it on. Without sophistication in the Inform stage, no other FinOps objectives are possible. As stated by the FinOps Certified Practitioner Training, “Cost Allocation…is the most important thing you will do as someone involved in FinOps.”
Optimize
In the Optimize stage, you make sure you’re using only the cloud resources you need to be using, you “rightsize” (correlate resource size with usage demands), and make long-term resource commitments (with associated discounts) based on this information.
As you can see, optimization applies to both usage and price, but these responsibilities fall on different teams. Everyone who uses the cloud is responsible for using it optimally, and the central FinOps team will leverage usage information to get the best price.
Operate
With wide FinOps adoption, sophisticated tooling in place, and a constant stream of accurate cloud cost data, teams can “Operate”: Judge cloud spend trends against business objectives, make improvements to cloud governance processes, enrich teams with more granular information.
Again, Inform → Optimize → Operate never stops. The strategic information you capture during the Operate stage will in turn produce a new Inform stage, reveal new Optimization opportunities, and create new benchmarks against which to Operate. The cycle never ends; improvement is always possible.
The Macro View
Each of these frameworks is happening concurrently, and progress (or regress) in one impacts the others.
Accuracy in the Inform stage enables teams to make savvy Iron Triangle tradeoffs. A certain level of cloud spend optimization marks an organization’s advancement from the Crawl stage to the Walk stage. Healthy reporting in the Operate stage enables more accurate allocation, even more informed tradeoffs, finer optimizations, and so on, until your FinOps practice is running at a gallop.
Inform → Optimize → Operate is the iterative process by which teams make smart Iron Triangle tradeoffs. The more iterations, the more impactful your decisions, and the more you advance through the overarching Crawl → Walk → Run journey.
Importantly: Each of these frameworks — and indeed, the entire FinOps journey — lives or dies by accurate cost allocation.
If you don’t know how much you’re spending, what you’re spending it on, and how it’s changing over time, you can’t make informed tradeoffs, and you can’t advance to Optimization and Operation. Cost allocation is the most valuable FinOps currency.
Inform → Optimize → Operate
Inform → Optimize → Operate is the iterative process by which FinOps practices evolve. The process doesn’t happen just once; it’s an ongoing cycle, repeatable at every stage of FinOps maturity, resulting in more valuable information and more streamlined processes.
Inform
The goal of the Inform stage is to enhance cloud cost visibility and allocation. Understand how much you’re spending and what you’re spending it on. Without sophistication in the Inform stage, no other FinOps objectives are possible. As stated by the FinOps Certified Practitioner Training, “Cost Allocation…is the most important thing you will do as someone involved in FinOps.”
Optimize
In the Optimize stage, you make sure you’re using only the cloud resources you need to be using, you “rightsize” (correlate resource size with usage demands), and make long-term resource commitments (with associated discounts) based on this information.
As you can see, optimization applies to both usage and price, but these responsibilities fall on different teams. Everyone who uses the cloud is responsible for using it optimally, and the central FinOps team will leverage usage information to get the best price.
Operate
With wide FinOps adoption, sophisticated tooling in place, and a constant stream of accurate cloud cost data, teams can “Operate”: Judge cloud spend trends against business objectives, make improvements to cloud governance processes, enrich teams with more granular information.
Again, Inform → Optimize → Operate never stops. The strategic information you capture during the Operate stage will in turn produce a new Inform stage, reveal new Optimization opportunities, and create new benchmarks against which to Operate. The cycle never ends; improvement is always possible.
The Macro View
Each of these frameworks is happening concurrently, and progress (or regress) in one impacts the others.
Accuracy in the Inform stage enables teams to make savvy Iron Triangle tradeoffs. A certain level of cloud spend optimization marks an organization’s advancement from the Crawl stage to the Walk stage. Healthy reporting in the Operate stage enables more accurate allocation, even more informed tradeoffs, finer optimizations, and so on, until your FinOps practice is running at a gallop.
Inform → Optimize → Operate is the iterative process by which teams make smart Iron Triangle tradeoffs. The more iterations, the more impactful your decisions, and the more you advance through the overarching Crawl → Walk → Run journey.
Importantly: Each of these frameworks — and indeed, the entire FinOps journey — lives or dies by accurate cost allocation.
If you don’t know how much you’re spending, what you’re spending it on, and how it’s changing over time, you can’t make informed tradeoffs, and you can’t advance to Optimization and Operation. Cost allocation is the most valuable FinOps currency.
The Macro View
Each of these frameworks is happening concurrently, and progress (or regress) in one impacts the others.
Accuracy in the Inform stage enables teams to make savvy Iron Triangle tradeoffs. A certain level of cloud spend optimization marks an organization’s advancement from the Crawl stage to the Walk stage. Healthy reporting in the Operate stage enables more accurate allocation, even more informed tradeoffs, finer optimizations, and so on, until your FinOps practice is running at a gallop.
Inform → Optimize → Operate is the iterative process by which teams make smart Iron Triangle tradeoffs. The more iterations, the more impactful your decisions, and the more you advance through the overarching Crawl → Walk → Run journey.
Importantly: Each of these frameworks — and indeed, the entire FinOps journey — lives or dies by accurate cost allocation.
If you don’t know how much you’re spending, what you’re spending it on, and how it’s changing over time, you can’t make informed tradeoffs, and you can’t advance to Optimization and Operation. Cost allocation is the most valuable FinOps currency.
5. The Difference Between Discount Optimization And Cost Intelligence
Early in their FinOps journeys, many people view “FinOps” and “cost optimization” as synonyms. It makes sense: If the goal is to maximize the ROI of your cloud investment, doesn’t that mean optimizing your cloud costs?
In one way, absolutely. If we understand “optimization” to mean “spending as little as possible to get the highest possible impact,” there are proven ways to reduce your cloud costs without sacrificing performance. Fewer dollars making the same impact = a higher overall ROI.
The first wave of cloud cost management solutions exploited this idea to the max. They took what you were spending in the cloud, applied common discount instruments — savings plans, convertible instances, and reserved instances — and reduced your overall bill by a comfy percentage.
So, what’s the problem?
The Limitations Of An Optimization-Only Approach
The central problem is that optimization doesn’t give you any visibility.
Optimization doesn’t tell you what parts of your business are most and least profitable. It doesn’t tell you if one of your customers is driving higher-than-normal levels of cost. It doesn’t break down the costs of individual product features and show you how to fix architectural inefficiencies.
Then, after the discount, there’s no feedback loop. You get a discount, and the more sophisticated optimization platforms (like ProsperOps, a one-time CloudZero partner) will automate your discounts over time to make sure you’re always getting the best possible deal.
But unlike cost intelligence, optimization alone doesn’t have business outcomes beyond the best possible deal. Outcomes like:
- Creating a cost-conscious engineering culture – Feeding cost information to the engineers who build your products, and giving them tools to build cost-efficiently.
- Cost anomaly detection and resolution – Pinging the relevant engineering teams when cloud costs spike, and pointing them to the resource(s) responsible.
- Pricing model adjustments – Showing you which customers cost the most in the cloud, and letting you adjust your pricing models/contracts accordingly.
- Usage optimization – There are really two prongs of optimization: cost optimization and usage optimization. The former refers to how much you’re spending (a dealmaking issue); the latter refers to how much your organization uses the cloud (an issue of personal habits). Cost optimization tools don’t help you with the latter.
Allocate Before You Optimize
Optimization is an essential part of any FinOps journey. It just shouldn’t be the only part of it — and it should come after cost allocation, not before.
You can think of the relationship between allocation and optimization in gardening terms.
Optimization is like paring, while allocation is like understanding the identity (and relevance) of each plant. If your garden were entirely weeds, optimization wouldn’t do much good — it would give you fewer unsightly plants to deal with, but it wouldn’t fix the underlying problem.
Once you’ve identified which plants you want to grow and understood what size you want them to be, then you can start paring them down to create an optimal garden. The more your garden grows, the more important this sequence becomes: choosing the right plants, understanding their value, and making sure they’re the right size for the role.
For a well-tended FinOps garden, the importance of starting with allocation can’t be overstated. In fact, the FinOps Foundation calls it the “most important tool for FinOps practitioners.” The next chapter investigates why.
6. Why Cost Allocation Is The Most Important Tool for FinOps Practitioners
In 2020, the FinOps Foundation rolled out the FinOps Certified Practitioner training, a crash-course for anyone looking to understand the lifecycle of FinOps maturity. In the training’s tenth module, there’s a particularly powerful quote:
“Cost allocation (or attribution) is the most important thing you’ll do as someone involved in FinOps.”
What makes cost allocation so important?
Cost Allocation: Your Cloud Investment’s “Photo Negative”
Cost allocation is centrally important because it addresses the cloud’s central financial challenge. In case you need a refresher, the challenge is thus:
- Each cloud user at your organization (i.e., every engineer) has the power to make purchases according to their development needs.
- Cloud providers’ native billing tools show you how much you’re spending overall, but don’t give you a clear view into what you’re spending it on or why your spend changes over given intervals of time.
- Without sophisticated tooling, it’s near-impossible to make a usable record of every single cloud expenditure as it happens — which leaves organizations assessing their cloud habits after the fact.
This all makes it very difficult to understand the true nature of your cloud investment. You can get a bird’s-eye view of how much you’re spending overall, but it’s harder to tell how much you’re investing in each customer, product, feature, etc. Without this understanding, it’s impossible to advance through higher states of FinOps maturity.
Cost allocation means automatically tracking cloud expenditures and assigning them to business units.
Cost allocation is typically expressed as a percentage: 50% cost allocation means you can attribute half of your cloud spend to relevant sources and investments; 100% cost allocation means isolating every single instance of cloud expenditure, understanding who’s responsible for each, and assigning each expense to the relevant products, features, teams, etc.
From this information, you can extract the ROI of your cloud investment. You already know how much revenue your customers and products are producing, and now, you can compare those revenue figures to how much you’re spending in the cloud on each. With a clear sense of cloud ROI, you can make informed, proactive modifications as necessary.
Think Negative
Cost allocation is to your cloud investment what negatives are to film photography.
When you take a photo with a film camera, the light entering the shutter darkens the film, producing an image whose lightness and darkness values are the opposite of their “real” values. The film development process reverses the values of the negative to get the “positive” image ( i.e., how the image actually looks).
Here’s what that means visually for black-and-white photos (negative on the left, positive on the right):

The same process happens in color photography, where the negative consists of the positive’s complementary colors, the colors opposite the real ones on the color wheel:

How does this relate to cost allocation?
Poor cost allocation is like relying on the accuracy of memory vs. photo negatives. Memory gives you a general sense of what happened, but it omits granular details.
Then there’s memory distortion, where people’s biases cause them to remember events differently from how they actually happened. Trying to get an accurate idea of an event using only the memories of the people involved is extremely difficult (just ask the justice system).
The “Peanut Butter Spread” — Or, The Perils Of Low-Res Cost Allocation
Without 100% cost allocation, organizations use makeshift approaches to parsing their cloud spend. They either move slowly, inaccurately, or both.
Working with customers, we’ve heard numerous stories about what engineering teams without cost allocation tooling do when asked to explain cloud cost trends. It’s not uncommon for teams to devote 8-10 hours a week to satisfying these requests, producing only a fuzzy image of what actually took place.
Organizations trying to avoid wasting engineering resources on cloud spend tracking often use the “peanut butter spread” approach. Here, they divide their cloud bill by the number of customers (or products, or teams, etc.) and use average cost to calculate unit cost. They “spread” the cost equally across all customers.
It’s impossible for all customers to cost the exact same amount — especially for organizations serving multiple types of customers (enterprise customers and SMBs, for example) and so cost data divined from the peanut butter spread approach cannot be precisely accurate.
The peanut butter spread approach obscures the real cost of each customer, which makes it impossible to know how much you’re making on each customer — or if you’re losing money on any customers (much more common than you might think).
The Invention Of The Camera
Cost allocation is extremely difficult — especially when relying only on tagging, which is stymied by shared resources (Kubernetes, multitenancy) common to today’s cloud-native architecture.
To break out of the peanut butter approach and the limits of tagging, you need to break down shared resources, calculating actual usage by customer, product, or whatever telemetry-driven metrics are most relevant to your business.
Poor cost allocation leaves you making concrete business decisions based on imprecise data.
100% cost allocation gives organizations high-resolution negatives of their cloud investment. You can see exactly what you spent on exactly what resources at exactly what time, with no manual labor, and no room for opinion or dispute.
Then, just as film developers use image negatives to develop the “real” image, leaders use cloud cost allocation metrics to develop the “real” image of their cloud ROI.
Undoctored photos and videos give people a perfectly accurate account of an event. 100% cost allocation gives organizations a perfectly accurate account of their cloud investment. Thus, the advent of sophisticated cost allocation tooling is as momentous for FinOps professionals as the advent of the camera was for artists, agents of the law, and, well, everyone else.
It’s no wonder that percentage of cost allocation is a central metric in evaluating your stage of FinOps maturity. The better your cost allocation, the more intimately you can understand the true value of your products, your customers, your people — all the factors in the equation of enterprise value.
The more sophisticated your cost allocation processes, the less time you spend developing the cloud ROI image — like going from film photography to digital photography. Over time, sophisticated cost allocation tooling enables you to make more accurate forecasts, contextualize cloud spend trends more easily, and make strategic business decisions more quickly.
7. 4 Methods Of Cost Allocation, From The Conventional To The Creative
Cost allocation is as much an art as it is a science. Elite cost allocation depends on having the right tools, but it also depends on finding the right lenses through which to view your data.
While there are commonalities in how organizations parse and sort their data, there is no one-size-fits-all approach. Selecting and establishing the most relevant views (we call them Dimensions) depends on your business model, the financial metrics that define success for you, and the factors most significantly impacting those metrics.
Here, we give you an overview of different cost allocation methods used by CloudZero customers.
Some Dimensions (e.g., cost per customer) are broadly useful, whereas others (e.g., cost per game) show how deeply you can customize your cost allocation approach. In each case, we arrived at these Dimensions only after an overview of what drove their businesses and what views were most crucial.
4 Cost Allocation Methods Used By CloudZero Customers
Malwarebytes: Cost Per Product
Malwarebytes is one of the world’s foremost providers of anti-malware software. Like many SaaS companies, they use multi-tenant architecture in which multiple products run on the same underlying cloud infrastructure.
While multi-tenant architecture enables speedy innovation, it also makes it difficult to trace cloud costs to specific products. So, before adopting a cost allocation solution, it was a guessing game as to how much cost each of Malwarebytes’s various products and features were driving were driving the most value — and how engineers might economize the more costly products.
Thus, a metrical requirement for Malwarebytes’s FinOps journey was cost per product. Upon getting it, they not only used it to drive cost-consciousness among engineers, but to drive “constructive conversations about how to efficiently design new features and products,” per Brian Morehead, VP of Cloud Operations at Malwarebytes.
Drift: Cost per feature
As a conversational marketing platform, Drift’s effectiveness relies on their ability to ingest large amounts of data and use it to tailor targeted customer chat experiences. Ingesting large amounts of data is costly — especially given the freemium features Drift uses to give new customers a taste of their value.
Driven by AWS, Drift’s COGS were mounting to the point that the company established a team called the “COGS Hunters.” Their mission: Identify the sources of mounting product costs and get them under control.
To do so, Drift needed to dive one step below the product level, to the cost per feature metric. Upon getting this visibility, Drift was able to reduce the AWS cost of a key freemium feature by 80%. So, instead of radically altering their business model in reaction to mounting AWS costs, they kept the product free and running more cost-efficiently than ever.
SmartBear: Cost per customer
SmartBear offers numerous apps through the Atlassian marketplace (basically an App Store for businesses). Because of how broadly useful their tools are, they have customers ranging from tiny customers using the free tier of Jira to enterprise-cloud solutions with 100,000 users.
Naturally, this customer diversity drives immensely different costs. For SmartBear to stay financially healthy as they scale, they recognized the need for a cost allocation tool that delivered accurate cost per customer information.
Once they did, they cleared away infrastructural excess, raised revenue without expending more engineering resources, and even altered their go-to-market strategies for different customer segments.
Beamable: Cost per game
One of the more creative approaches to cost allocation came from Beamable, a platform that provides infrastructure to video game designers. That more people play video games than ever is great news for their business — so long as they could keep their cloud costs under control.
Like SmartBear, Beamable’s customers use their platform in very different ways. Game design falls along a broad spectrum of complexity; the more complex a game, the more underlying infrastructure it uses, and therefore the more it costs Beamable.
Thus, Beamable decided on cost per game as a centrally important metric. They even got even more sophisticated, analyzing time per API call (in milliseconds) to calculate cost per service per game per customer, showing just how nuanced cost dimensions can get.
Allocated Spend With Dimensions
The overarching point here is that the Dimensions you use in your cost allocation approach should relate to your central business challenges and objectives.
If you’re a feature-heavy platform like Drift, cost per feature may be a useful dimension. If you serve a variety of customer types like SmartBear, cost per customer may be a better place to start.
There’s no limit to the number of ways to configure your data. The more mature your FinOps practice, the deeper and more nuanced your dimensions will grow.

