

IDC predicts a ten-fold increase in data by 2025, which should surprise just about no one. We are all producing more and more data every day—more data than ever before, with no slowdown in sight.
Recently we joined forces with our friends over at CHAOSSEARCH to deliver a webinar on the topic of Big Data Done Right—How to Spend Less While You Store & Analyze More. In this webcast, we discussed some best practices around big data storage, transfer, and access. We shared some of the common pitfalls that lead to unnecessary costs and how to avoid these by increasing visibility and optimizing your data querying and access methods.
Today, we want to share some of the topics and lessons from that webinar with you.
Big Data Costs: The Four Horsemen of the Big Data Cost Apocalypse
There are four main areas where we see big data costs arise. However, most people focus too much on certain areas (that may not even be the biggest cost centers) and not enough on other, more complex and potentially expensive areas. Let’s look at these in detail:
Storage
Interestingly, this is the area that people generally worry the most about. Where are we going to put all that data, and how much will it cost? However, storage is in many ways the cheapest area of big data management, and the easiest to understand. Of course you want to make sure you optimize your data storage, but it’s not necessarily where you want to focus your cost reduction efforts.
Movement
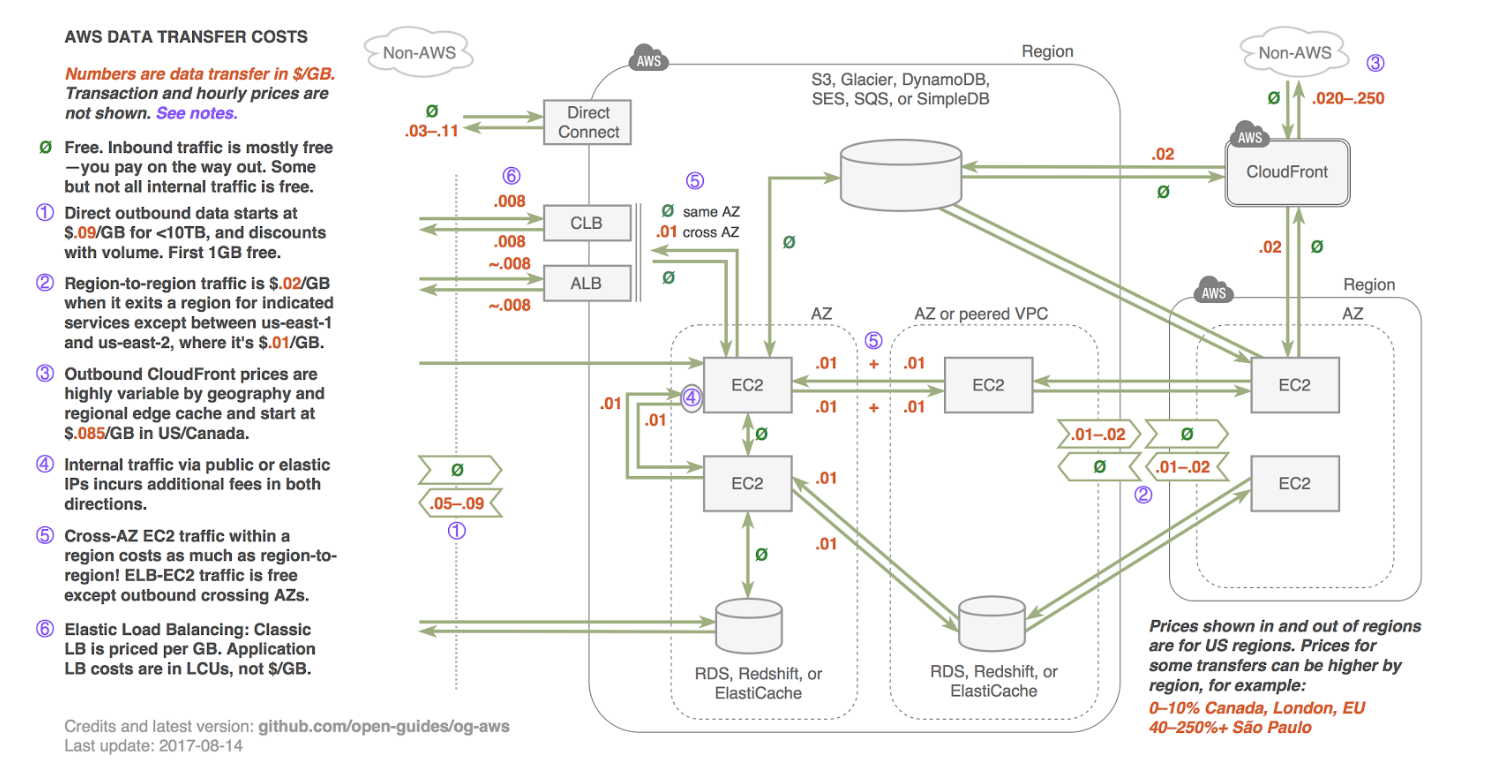
On the other hand, many people forget about data movement. The network is free, right? Yet there are some extremely complex rules that drive data movement costs, which can be highly variable and unpredictable. This area can be almost impossible to calculate up-front, but it needs to be part of your plan around big data. Here’s a summary of the cost of AWS data transfer.
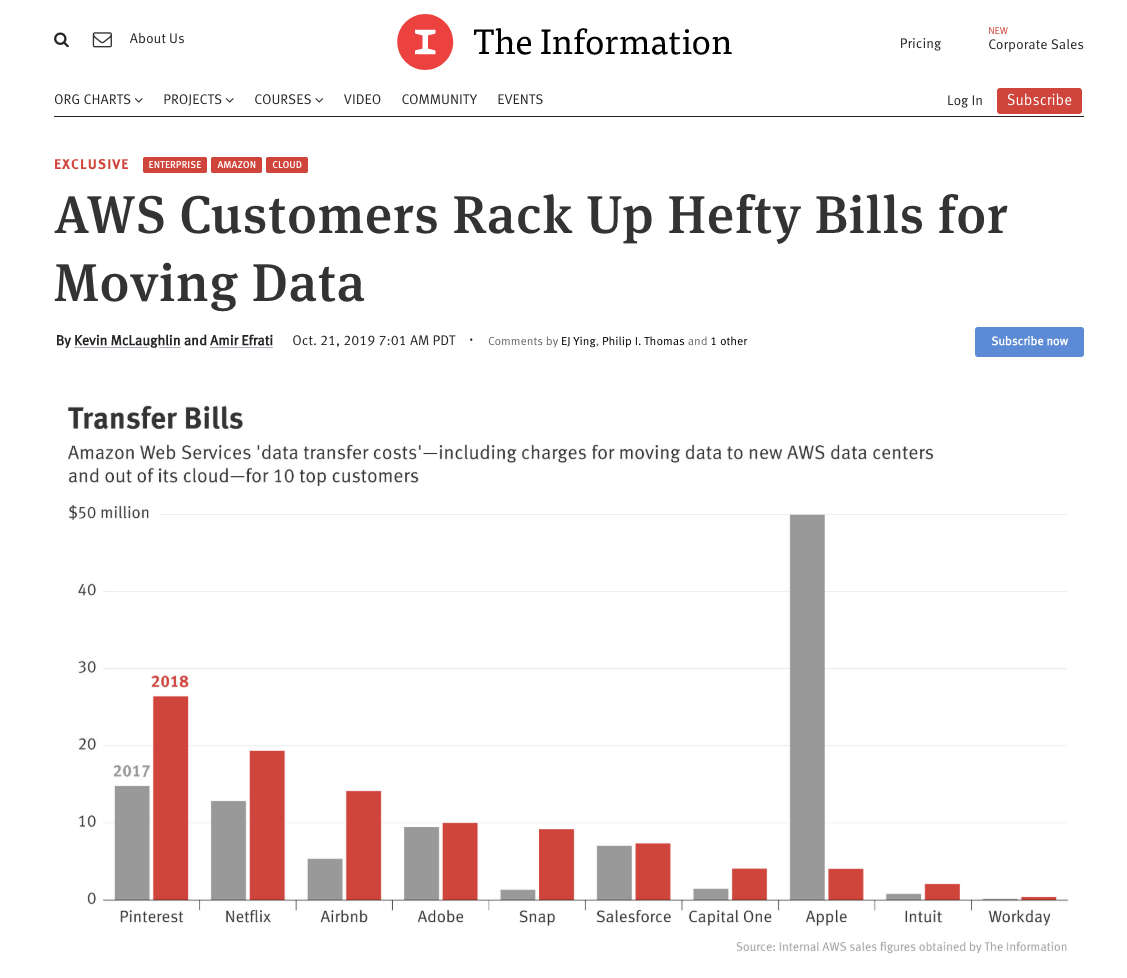
The Information recently covered how these costs are impacting some of the largest tech companies.
Shaping
We call this the “dirty little secret” of big data. In all likelihood, it’s where you will spend the most time, and it can come with some potentially huge upfront costs.
Accessing
What we often see is that companies don’t worry about access until it’s too late. Designing for scale is very challenging, and accessing data is ultimately the most expensive thing you’ll do.

Where is All This Data Coming From?
In a nutshell, machine-generated data is driving growth. Microservices based architecture (think: Docker, Kubernetes) are increasingly common. This enables teams to ship microservices more efficiently, but it also means they must move to much larger instances. Costs can grow dramatically as architecture increases.
If this isn’t properly accounted for and planned around, it can lead to massive cloud cost spikes. Again, a lot of these costs come from processing, managing, and moving data.
When it comes to containers, the total cost of your cloud is rolled up and buried in an EC2 bill. This makes it difficult to break out by node, pod, or container. It’s also very challenging to account for shared resources.
In the world of serverless, costs are spread out across numerous services. This makes it difficult to understand downstream side effects. For example, How do you figure total cost per transaction? Your Lambda cost may be low, but your total cost of system may be quite high.
When we are thinking about processing huge amounts of data, there are all sorts of downstream effects.
Big Data Costs: Your Most Expensive Blind Spot
Here’s another way to think about it: Cost is very likely the most expensive thing you aren’t monitoring. Consider the other aws cloud cost monitoring you have in place. If your site goes down or transactions start failing, you’ll probably know about it within a few seconds. If an unexpected cloud expense comes along, odds are good the team responsible for it won’t even know about it until a month or even a whole quarter later, at which point the damage is done.
It’s really important to be able to connect “actions” (e.g. engineering choices) to “cost of actions” (e.g. the cloud bill). If your organization doesn’t have the ability to do that, in the age of Big Data, your cloud bill will continue to go up and up with little control on your part.
You need live aws cloud cost monitoring.
AWS Cloud Cost Monitoring for Big Data: Where to Start
If you’re overwhelmed by the challenge of AWS cloud cost monitoring and managing big data costs, you’re not alone. Here are four places to begin your strategy and focus on controlling and predicting these cloud costs.
Review Common Offenders
Cost spikes often come from misused or misconfigured services. Some common offenders include CloudWatch logs, Athena, and managed NAT Gateway.
Enable S3 Metrics
Make sure you are using Amazon S3 tiered access for storage. Enable S3 metrics to better understand how your data is being stored. If you don’t need access to data but can’t delete it for legal or other reasons, consider Glacier for cold storage to save on costs.
Review Access Patterns
Assess whether you have the right data engine for the access pattern that you actually need.
Become an Educated Buyer
It’s key for your operations and engineering organizations to understand that every line of code is a buying decision. Thousands of dollars can easily be spent in minutes or hours, so baking this understanding into their decision-making process, while not easy, will pay dividends in terms of caved costs. In other words, you should track cloud spend as a first class metric (and ensure that clear ownership is assigned).
Big Data Can Be a Big Value Driver
As with any other cloud costs, when Big Data-related costs are directly tied to your pricing structure, it becomes possible to scale with fewer growing pains. Big Data costs may feel massive, but if you can demonstrate that they are driving value and revenue for the business, and that no unexpected or unnecessary costs are taking place, then you can remove some of the burden that these big costs may otherwise impose.

The Cloud Cost Playbook
The step-by-step guide to cost maturity



