
Snowflake and Databricks are both robust data platforms. Both are built for speed, scale, and cloud-native applications. They also prioritize efficiency and adherence to strict data protection protocols.
Yet each adopts a distinct approach and features suited to its architecture and various use cases. It is these differences that can make all the difference in the way your data is processed, analyzed, reported, and more.
That said, we’re sharing the key differences in this post to help you pick the best.
What Is Snowflake?

Snowflake stands out in the data warehousing market with its innovative cloud-native architecture, speed, and efficiency. Consider these:
Key Snowflake features include:
Data cloud
Snowflake supports data lake, data engineering, and data warehousing functions as a Software-as-a-Service (SaaS) offering. The data platform also works across the three major cloud providers; Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Your pick.
Cloud-native architecture
Snowflake is designed specifically for the cloud and separates storage and compute resources. This means you can scale each component independently, providing flexibility and cost efficiency for diverse workloads.
Pay-as-go pricing
You pay only for the storage and compute resources you actually use. This model contrasts with alternatives such as Databricks and Amazon Redshift. These bundle costs for compute and storage, potentially leading to less flexibility and transparency in pricing.
Ease of use
Snowflake boasts a user-friendly interface that simplifies setup and management than the competition.
Check out this Snowflake guide to learn more about how the Snowflake data cloud works.

What Is Databricks?
Databricks is particularly seamless at handling structured, semi-structured, and unstructured data through a lakehouse architecture. It also integrates deeply with Apache Spark, making it a unified platform for data engineering, machine learning, and analytics. And there’s more.
Key features of Databricks include:
A unified data platform
Databricks integrates various data workflows into a single platform. This enables seamless collaboration among data engineers, scientists, and analysts more effectively than in more siloed environments like Snowflake and Redshift. These two focus primarily on data warehousing and SQL analytics.
Built on Apache Spark
Databricks also leans heavily on its open-source roots (Apache Spark). This enables Databricks to process vast amounts of data in parallel, making it ideal for real-time analytics and complex data processing tasks.
Scalability and performance
The platform’s cloud-native design allows for dynamic scaling of compute resources based on workload demands. This ensures that users can handle varying data sizes without manual intervention. This can be more cumbersome in, say, Redshift due to its fixed cluster sizes.
Advanced security tools
Databricks offers robust security measures. These include role-based access control (RBAC) and encryption for data at rest and in transit. For enterprises handling sensitive information, these features ensure compliance with stringent security standards.
Multi-cloud flexibility
Unlike Snowflake and Redshift, which are often tied to specific cloud environments (AWS for Redshift), Databricks supports multi-cloud deployments. This means you can use your existing cloud infrastructure while benefiting from Databricks’ advanced analytics capabilities.
Related Reads:
Snowflake Vs. Databricks: 7 Key Differences To Watch Out For
When it comes down to choosing between Databricks and Snowflake, here is a quick comparison table to get you started. We will expound on a couple of these differences after this quick overview.
Snowflake | Databricks | |
Description | A cloud-native data warehousing platform. | A unified data lakehouse built on Apache Spark with strong emphasis on real-time analytics and AI/ML. |
Architecture | Hybrid architecture (shared disk and shared nothing) with three layers: cloud services, query processing, and database storage. Separates compute and storage. Each can scale individually, allowing for flexible performance across a wide range of workloads. | Combines data lake and data warehouse with Delta Lake and Apache Spark. Supports unified data engineering and ML. |
Supported data types | Structured and semi-structured data, such as JSON, Parquet, Avro, and XML. | Structured, semi-structured, and unstructured data, excellent for large-scale real-time analytics and AI/ML. |
Programming languages supported | Primarily SQL (Snowflake SQL); supports Java, Python, and R through Snowpark, and JavaScript for UDFs. | Broader set of programming languages, including Python, Scala, Java, R, and SQL. Comes with built-in AI/ML features, such as MLflow, an open-source platform that streamlines the entire machine learning lifecycle. |
User friendliness | Offered as a SaaS with a straightforward setup process and management. | Steeper learning curve but robust capabilities for advanced users. |
Data processing | Batch processing that’s optimized for structured data. Slower with semi-structured data. | Designed to support both batch and stream processing. Optimized for performance with Delta Engine. |
Performance | Offers high performance for conventional BI and analytic queries with strong concurrency handling. | Built for high-performance data processing, including large-scale ETL, streaming, and real-time analytics. |
Autoscaling | Automatically scales compute clusters based on workload. Offers elastic scaling to handle concurrency. | Expect intelligent serverless autoscaling with optimized cluster utilization for data processing. |
Multi-cloud deployment | Available on AWS, Azure, and GCP. Supports cross-cloud operations. | Also available on AWS, Azure, and GCP but with support for hybrid and multi-cloud deployments. |
Data sharing | Enables secure data sharing across different organizations and accounts without moving your data. | Uses Delta Sharing for efficient data exchange across teams or organizations. |
Security and compliance | Expect robust end-to-end encryption, multi-factor authentication, data governance, and compliance (SOC 1, 2, 3, HIPAA). | Offers role-based access control (RBAC), encryption at rest and in transit, and compliance with industry standards (SOC 2, GDPR). |
Integrations | Powerful integration with BI tools such as Tableau, Looker, and PowerBI. Supports ELT and batch processing. Relies on third-party services for some functionalities. | Native integration with Apache Spark, Delta Lake, and other data science tools. Supports real-time streaming. Strong integration with ML frameworks (TensorFlow, PyTorch) and other data tools. Includes Unity Catalog for governance. |
Machine Learning support | Limited ML support through Snowpark for Python, compared to Databricks. You may require an external ML platform. | Full ML lifecycle support with native integration for popular frameworks (MLflow, TensorFlow, PyTorch). |
Pricing model | Pay-as-you-go for storage and compute; separate charges for each. Billing is on a per-second usage of Compute Credits. Provides multiple pricing tiers (Standard, Enterprise, Business Critical, VPS). | Pay-as-you-go with per-second billing. Supports committed-use discounts for cost savings. The usage-based pricing offers options for jobs and interactive clusters. |
Best use cases | Ideal for data warehousing, analytics, and secure data sharing. Strongest in Business Intelligence (BI) use cases and structured data analysis. | Data engineering, machine learning, real-time analytics, streaming data processing. Excels in data lakehouse architectures. |
Snowflake Vs. Databricks: Use Cases
The difference in use cases stems from each platform’s design philosophy.
Snowflake’s architecture is optimized for SQL-based analytics. Expect to perform complex analytical queries quickly, benefiting from its automatic scaling and performance optimizations. This makes it suitable for generating reports, dashboards, and other BI applications where speed and ease of use are paramount. Additionally, Snowflake supports data ingestion without extensive ETL processes.
Machine learning (ML) capabilities are also available. But, they typically require external tools like Snowpark. Ultimately, Snowflake’s architecture is best-optimized for SQL queries and is not natively designed for extensive ML or data science workloads.
Databricks’ ability to handle both structured and unstructured data with minimal preprocessing gives it an edge in data science and ML, where flexibility and computational power are key.
The lakehouse is built on Apache Spark and designed to handle large-scale data processing and ML tasks. This makes it ideal for teams that need to build, train, and deploy machine learning models.
Also, tools like notebooks and robust ETL capabilities encourage collaboration among data scientists and analysts. Its architecture allows for extensive customization and scalability, which is crucial for handling large datasets and complex algorithms in ML workflows.
Databricks is also ideal for advanced analytics tasks such as real-time streaming, recommendation engines, and complex data transformations.
Pricing Comparison For Databricks Vs. Snowflake
Snowflake and Databricks both offer usage-based, pay-as-you-go pricing models. But as you’ll notice below, each product’s cost factors vary, making them significantly different.
Snowflake pricing is divided into three primary components: compute, data storage, and data transfer (paid for separately).
- Snowflake compute costs. Snowflake charges for compute resources based on the time your virtual warehouses are active and their size. Also:
- Billing occurs per second, and users consume “Snowflake credits” when running queries or performing tasks. The cost per credit varies depending on factors such as the Snowflake edition, cloud provider, and region you select.
- Serverless compute, used for tasks like Snowpipe and materialized views, is also billed per credit hour.
- Unused credits for cloud services, such as query parsing and metadata management, are often discounted if they make up less than 10% of daily compute usage.
- Snowflake data storage costs. The costs depend on the amount of compressed data stored per month. Snowflake automatically compresses your data unlike Databricks and Redshift. Storage is billed at a flat rate per terabyte, typically ranging between $25 and $40 per terabyte per month, with potential discounts for Pre-Purchased Capacity. The exact rate depends on the cloud provider and region you pick.
- Snowflake data transfer costs. Data ingress (importing) is free. Egress (exporting or transfers out) between regions or cloud platforms incurs fees. Snowflake pricing also depends on the purchase plan you pick; On-Demand (pay-as-you-go) or Pre-purchased Capacity.
On-Demand is suitable for flexible, unpredictable workloads, while Pre-purchased Capacity provides discounts for customers committing to a fixed resource usage in advance.
Want to dive deeper into Snowflake vs Databricks pricing models? Find out how Databricks pricing works here and how Snowflake pricing works here.
Databricks offers a 14-day trial compared to 30 days for Snowflake. However, Databricks Community is a free, open-source edition for small-scale workloads.
- A Databricks Unit (DBU) is the basis of Databricks pricing. This is a credits system, but while Snowflake credits apply only to compute, this DBUs system applies to all consumption. Factors such as the amount of data processed, memory, vCPU type, Region, pricing tier, and type of Databricks services you use determine the number of DBUs a workload consumes per hour.
- Databricks pricing tier (Standard, Premium, or Enterprise). For instance, prices can range from approximately $0.15 to $0.70 per DBU depending on the service and cloud provider.
- Databricks compute type. These include Jobs Compute for specific data engineering pipelines, SQL Compute for BI reporting and SQL queries, All-Purpose Compute for general data science and ML workloads, and Serverless Compute.
For instance, All-Purpose Compute starts at $0.40 per DBU in the Standard plan, while Jobs Compute starts at $0.07 per DBU for lightweight tasks. More advanced plans and features, like SQL Pro and Serverless, incur higher DBU rates ranging from $0.55 to $0.95 per DBU.
- Your cloud service provider (AWS, Azure, or Google Cloud) and region. Unlike standalone services like Snowflake, Databricks has native offerings for AWS, Microsoft Azure, and GCP.
- Databricks storage cost. Storage fees are charged based on the actual amount of data stored in the cloud, applicable to both managed and external storage options.
- Committed use contracts. Databricks offers discounts for users who commit to a certain level of usage over time. This can lead to significant savings compared to on-demand pricing.
Get the full Databricks pricing breakdown in one place here.
Snowflake and Databricks Integrations Compared
Snowflake operates as a Software-as-a-Service (SaaS) solution.
This means a fully managed data warehouse environment for you. Its architecture also seamlessly integrates with various BI tools such as Tableau, Looker, and Power BI. Additionally, expect built-in connectors for numerous SaaS apps, simplifying data extraction.
With Snowpark, for example, you can write custom applications in Python, Java, and Scala within the Snowflake ecosystem. The Data Marketplace is also available for secure data sharing.
However, Databricks’ Delta Sharing, an open-source protocol that allows data sharing across platforms, offers more flexibility than Snowflake’s proprietary sharing approach.
In addition, Databricks is also a Platform-as-a-Service (PaaS), emphasizing flexible data processing.
It operates on a Lakehouse architecture that combines features of data lakes and warehouses, enabling users to store data in various formats across multiple cloud platforms (AWS, Azure, Google Cloud).
This decoupled approach enables you to use your existing cloud infrastructure while integrating seamlessly with third-party solutions. Its integration capabilities extend to popular ML frameworks and tools like MLflow and TensorFlow for data scientists.
With Delta Lake, you get an open-source storage layer that supports ACID transactions (great for data lakes and lakehouses). Databricks also supports a broader set of data types, programming languages, and real-time processing capabilities through integrations with advanced ETL and ELT tools such as Fivetran and Hevo.
Ultimately, Snowflake and Databricks both support multi-cloud environments (AWS, Azure, and GCP).
However, Databricks provides more flexibility in terms of storage options since it can use cloud-native storage solutions like Amazon S3 or Azure Blob Storage. Meanwhile, Snowflake’s architecture is tightly integrated with its own managed storage solutions across AWS, Azure, and GCP.
Security And Compliance Comparison
Snowflake emphasizes a fully managed, SaaS-based architecture, offering automatic encryption of data both at rest and in transit.
- It features role-based access control (RBAC) for fine-grained permissions, network isolation via Virtual Private Cloud (VPC) peering, and features such as dynamic data masking to further protect sensitive information.
- Snowflake’s higher-priced tiers offer the best security features, allowing customization based on your needs.
- Snowflake is also compliant with major security standards and regulations like SOC 2 Type II, ISO 27001, HIPAA, and GDPR.
- Additionally, Snowflake’s native cloud model ensures security across all supported cloud environments (AWS, GCP, and Azure), with automatic data encryption by default.
Databricks also supports encryption at rest and in transit. But it operates a bit differently due to its underlying architecture built on Apache Spark and Delta Lake.
- Users can deploy their clusters within their own Virtual Networks (VNet) through VNet Injection, offering enhanced control over the networking environment. This feature makes it highly adaptable for organizations needing more control over security.
- Like Snowflake, Databricks adheres to SOC 2 Type II, ISO 27001, HIPAA, and GDPR standards.
However, since Databricks is more focused on big data and machine learning, it relies more on environments where integration with cloud object storage like AWS S3, Azure Blob Storage, or Google Cloud Storage is vital for compliance and security.
Which Platform Should You Choose?
With Databricks, you can unify your data team for data warehouse and data lake use cases, such as training AI/ML models with structured, semi-structured, and unstructured data.
If you need to manage structured and semi-structured data for business intelligence, analytics, and reporting, Snowflake could be for you.
We encourage you to test out each platform for yourself. You’ll have a much better idea of what your current needs are (and what they might be in the near future) once you do.
Want some inspiration? See our reasons for switching from Amazon Redshift to Snowflake here.
In any case, both offer free trials.
Understand, Control, And Optimize Your Snowflake And Databricks Costs The Smarter Way
Databricks or Snowflake, you’ll still want to keep your data costs low no matter which cloud service you choose.
It’s true that both platforms are designed to be efficient, but we’ve heard horror stories about avoidable overspending on both.
You don’t have to deal with this when you had this:
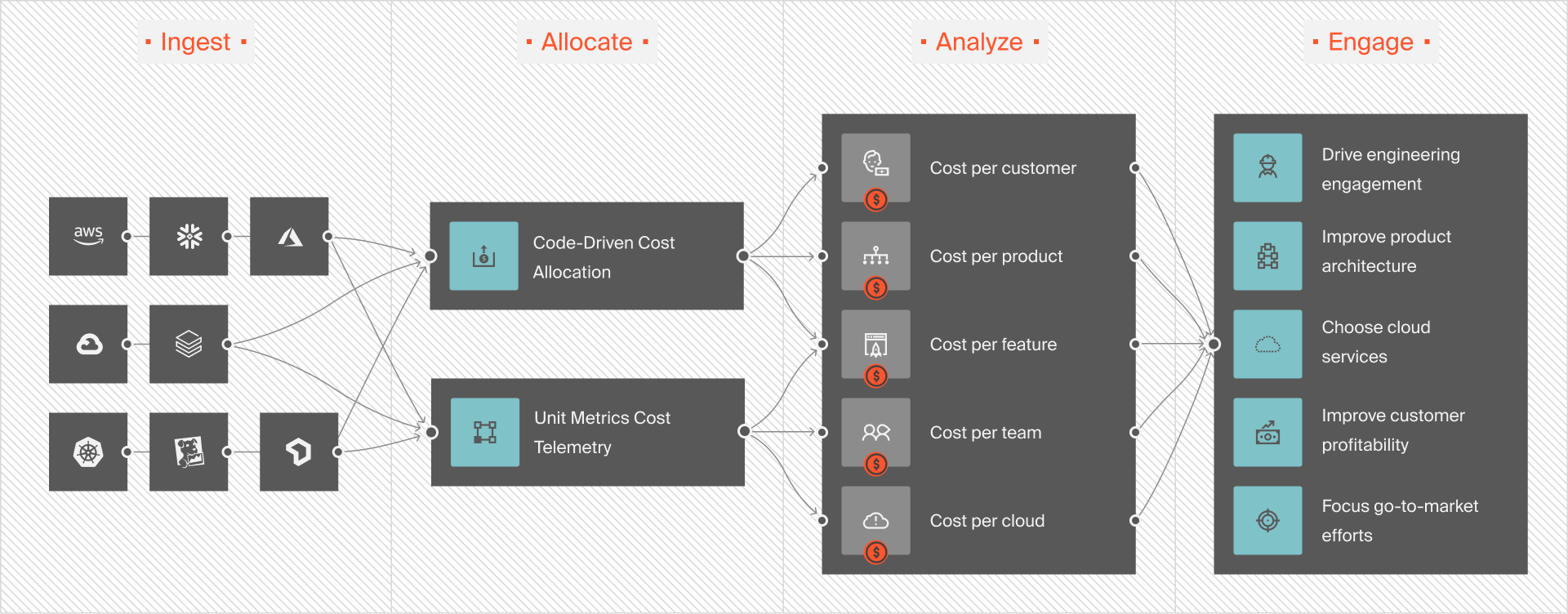
This is CloudZero’s Cloud Cost Intelligence approach. With it, you get a seamless Snowflake integration and an equally powerful Databricks integration. It takes just minutes to set up, after which you can:
- Allocate 100% of your Snowflake and Databricks costs and start tracking your data cloud costs in minutes, not weeks. No endless tagging is required.
- View your data cloud costs alongside your cloud spend (AWS, Azure, GCP, OCI) and platform costs (Datadog, MongoDB, New Relic, Kubernetes, and more). No additional tools or separate dashboards required here.
- Use custom dashboards to visualize your Databricks or Snowflake spend however you choose. See the people, products, and processes driving your data spend so you can act on it immediately.
- Get precise per-unit cost intelligence unlike anywhere else, such as cost per customer, request, feature and more.
We’ll let the numbers do the talking. In just one year, CloudZero saved Uptly $20 million and Drift $2.4 million. And now you can try CloudZero risk-free.  to experience CloudZero firsthand.
to experience CloudZero firsthand.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



