

Many companies are rapidly adopting cloud-native computing services, like containers, microservices, and serverless computing. Unlike monolithic applications, these technologies rely on distributed architectures.
Whether you are running them in the cloud, on-premises, or both, distributed systems consist of thousands or millions of processes and components. The challenge now is to make these complex systems’ inner workings visible, controllable, and improvable.
K8s is one of the most powerful tools for organizing, controlling, and maintaining containers, microservices, and their interdependencies.
Yet, Kubernetes is notorious for being difficult to manage using standard infrastructure monitoring tools. Here’s where Kubernetes observability comes in.
Table Of Contents
What Is Kubernetes Observability?
Observability in Kubernetes is the continuous process of using the metrics, events, logs, and trace data that a Kubernetes system generates to identify, understand, and optimize its health and performance.
Observability has its roots in Control Theory, and involves collecting, visualizing, and taking action based on a system’s output data. In DevOps, observability is unique in that it provides a way to collect, analyze, and pinpoint strengths, weaknesses, and their root causes in a complex system like Kubernetes. Monitoring, on the other hand, uses predefined criteria to understand a system.
Speaking of conventional infrastructure or application monitoring vs observability, how do the two differ?

What Is The Difference Between Observability And Monitoring In DevOps?
Monitoring and observability are often used interchangeably, but there are actual differences between them, including:
- Observability focuses on where, when, and why a particular event happens rather than just what is occurring and how (monitoring).
- Thus, observability plays a crucial role in root cause analysis or cause-and-effect assessment in systems and their components. Conventional application or infrastructure monitoring techniques largely highlight the current state of specific components of a system.
- Observability also emphasizes granularity rather than totals or averages as monitoring does.
- Moreover, observability involves studying variables, patterns, and changes as they emerge in a system, whereas monitoring typically involves gathering predefined telemetry data (metrics, logs, events, and traces).
- Besides, monitoring helps collect and analyze data that’s already known to relate to application, infrastructure, or network performance issues. In contrast, observability provides you with the context you need to detect, understand, and respond to issues you may not yet be aware of.
- Monitoring involves continually tracking and reporting the state of a system at a specific time. But observability involves using multiple streams of intelligence, including monitoring data, to discern the overall health and performance level of a system.
- While monitoring is reactive, observability is about continuous improvement or prevention.
- Also, monitoring involves more specific tasks, such as monitoring application performance, network performance, and security. Observability takes a context-based approach, in which teams analyze multiple factors to infer a system’s health.
However, observability and monitoring are closely linked because they reinforce each other.
Why Is Kubernetes Observability So Important?
As you might have already noticed, observability can be quite some work. But observability has equally massive benefits. Observability has even more importance in Kubernetes, given how complex the average enterprise’s K8s deployment is.
Here are seven of the most powerful benefits of K8s observability that become apparent almost immediately and over time.
- Improves Kubernetes visibility: Observability tools and techniques enable you to achieve deeper and clearer visibility into your Kubernetes system based on inputs and outputs.
- Observability minimizes complexity: It brings together health and performance data from multiple components, giving you a clear picture of your distributed Kubernetes system.
- Improves understanding: It also correlates telemetry data to provide a context that then helps you identify issues or opportunities and how they relate to each other.
- Helps prevent problems before they occur: By proactively interpreting observability data, you can detect potential issues before they escalate into problems that affect your Service Level Agreements (SLAs) or customer experiences.
- Provides actionable intelligence: Kubernetes observability solutions and techniques breakdown health and performance data into granular insights to improve root cause analysis.
- Helps reduce downtime: By enabling you to identify the root cause of a system issue, observability also helps minimize time to discover, fix, and restore operations back to normal.
- Minimizes unwanted surprises: Because observability also measures and presents “unknown unknowns”, it also helps bring attention to unexpected changes in a Kubernetes environment.
- Facilitates continuous improvement: You can swiftly adopt new lessons learned and apply them to subsequent deployments, such as predicting what issues you might encounter when updating Kubernetes, an add-on, or an application.
By understanding what is happening and why, Kubernetes observability helps you better visualize, manage, and optimize the unpredictable, distributed, and open-source nature of Kubernetes deployments.
Kubernetes Observability Challenges: What Can You Expect?
Kubernetes systems typically have lots of interconnected components, which means they have more potential failure points.
That also increases the number of areas you need to monitor.
Also, because these components are interdependent, you need to observe them simultaneously to understand their relationships. For instance, any change to a single codebase or system component affects your whole app and its dependencies.
Containers and microservices are highly dynamic, highly scalable, and generate massive volumes of health and performance data. So, applying observability to containers and microservices in real-time is challenging, especially without using robust Kubernetes observability tools.
Many Kubernetes monitoring tools only collect data at the app and infrastructure levels. Many Kubernetes monitoring tools also struggle to correlate, enrich, and contextualize data from hybrid cloud, multi-cloud, or multi-tenant architecture environments, making it less effective.
Yet, not all tools are created equal. Here are nine K8s observability solutions to help you better understand your Kubernetes environment.
9 Kubernetes Observability Tools Available Now
While some of the following tools provide full stack observability for Kubernetes others deliver specific capabilities, like Kubernetes cost observability.
1. CloudZero – Granular Kubernetes cost analysis
CloudZero is unique in that it is designed as an observability platform rather than a mere cost monitoring and optimization tool for Kubernetes. For example, CloudZero captures, enriches, and presents Kubernetes cost data from both your infrastructure and application without cost allocation tags.
Yet CloudZero delivers contextual cost data that includes costs from tagged, untagged, and untaggable resources to give you a complete picture of your Kubernetes costs.

Even better, CloudZero’s Kubernetes cost analysis lets you zoom into your cost data to view, understand, and share cost intelligence by K8s concepts, like:
- Cost per namespace
- Cost per pod
- Cost per cluster
- Cost per hour

In addition, you can view, understand, and take action on specific cost areas of your business, like:
- Cost per Kubernetes environment
- Cost per service
- Cost per deployment
- Cost per customer
- Cost per product
- Cost per product feature
- Cost per team, and more
CloudZero also enables you to compare Kubernetes costs with other cloud and software spend. You can combine K8s costs with AWS, Azure, GCP, Snowflake, and other costs within a single platform for easier analysis.

You also get real-time cost anomaly detection, intelligent alerting to reduce alert noise, and a highly visual platform to streamline analysis. Schedule a demo to see CloudZero’s Kubernetes cost analysis approach in action.
2. Prometheus – Open-source observability tool for Kubernetes

If you are looking for an open-source, full-stack observability tool with alerting capabilities, Prometheus can help.
Prometheus gathers metrics from your K8s containers, pods, nodes, services, and user applications. It is also cloud-native like Kubernetes and uses time-series metrics collection, built-in query language, and third-party exporters to capture and help make sense of your data.
You can also run it stand-alone, with a Kubernetes Operator, or in combination with a visualization tool like Grafana.
3. Grafana – Kubernetes observability dashboards and alerts
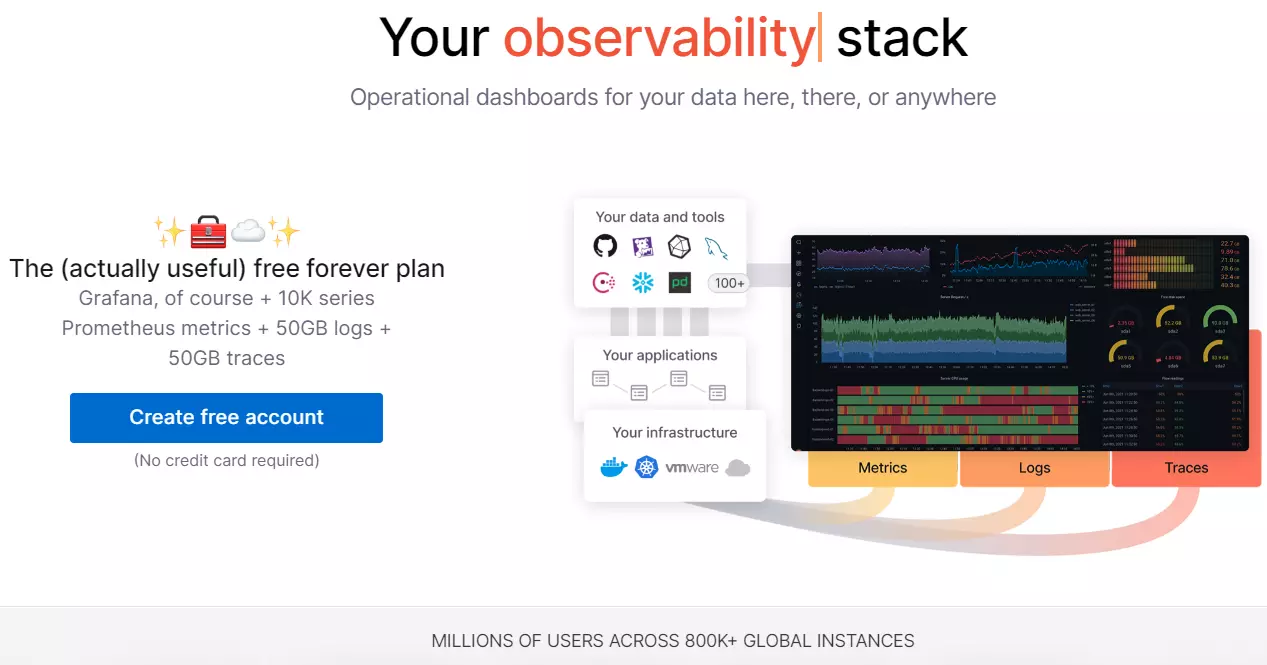
Available in enterprise and open-source versions, Grafana is an ultra-popular data visualization and analytics tools that works with both Kubernetes and Prometheus.
The paid Enterprise version offers authentication, premium support, and integrates with many commercial monitoring platforms, like AppDynamics (APM) and Datadog (full-stack monitoring).
The free, open-source version delivers a highly visual tool for exposing Kubernetes observability data (metrics, logs, and traces).
4. The ELK Stack – Open-source K8s observability stack
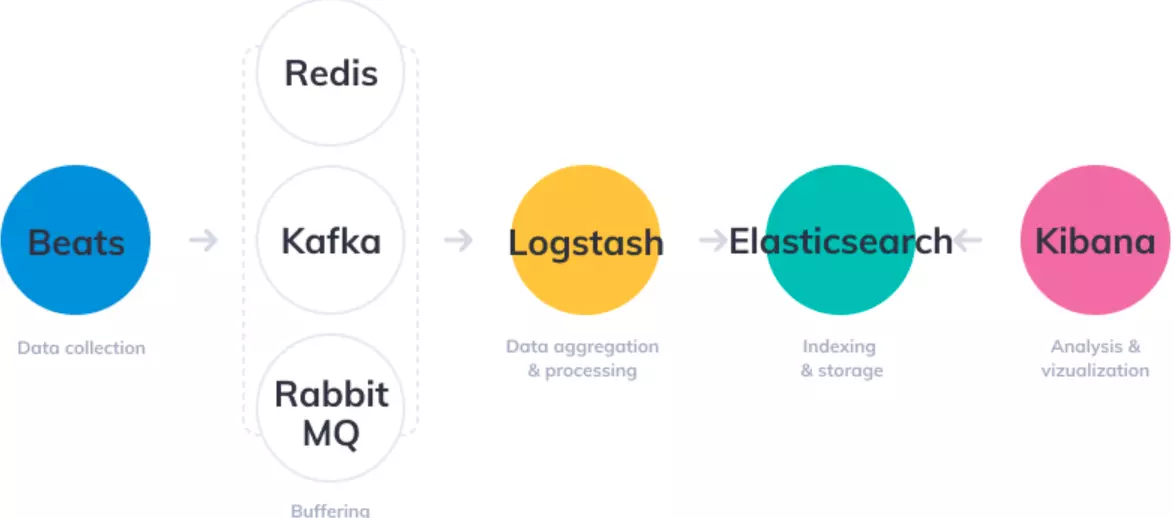
The ELK suite includes three open-source solutions: Elasticsearch, Logstash, and Kibana. Elasticsearch serves as a search and analytics engine.
Logstash provides a server-side (ingest) data pipeline. Logstash pulls data from multiple sources concurrently, transforms it, and then pushes it to a repository like Elasticsearch for analysis at the scale of your Kubernetes deployment.
Kibana visualizes observability data with graphs and charts. Beats, another component, eases shipping log data.
5. Splunk – Full-stack Kubernetes Observability
With Splunk, you get a quick, detailed, and hierarchical analysis of your K8s nodes, pods, and containers. Splunk scrapes your infrastructure and apps, gathers your K8s logs, and uses Artificial Intelligence to provide context to the health and performance of your Kubernetes clusters.
6. Instana – Full stack K8s observability platform
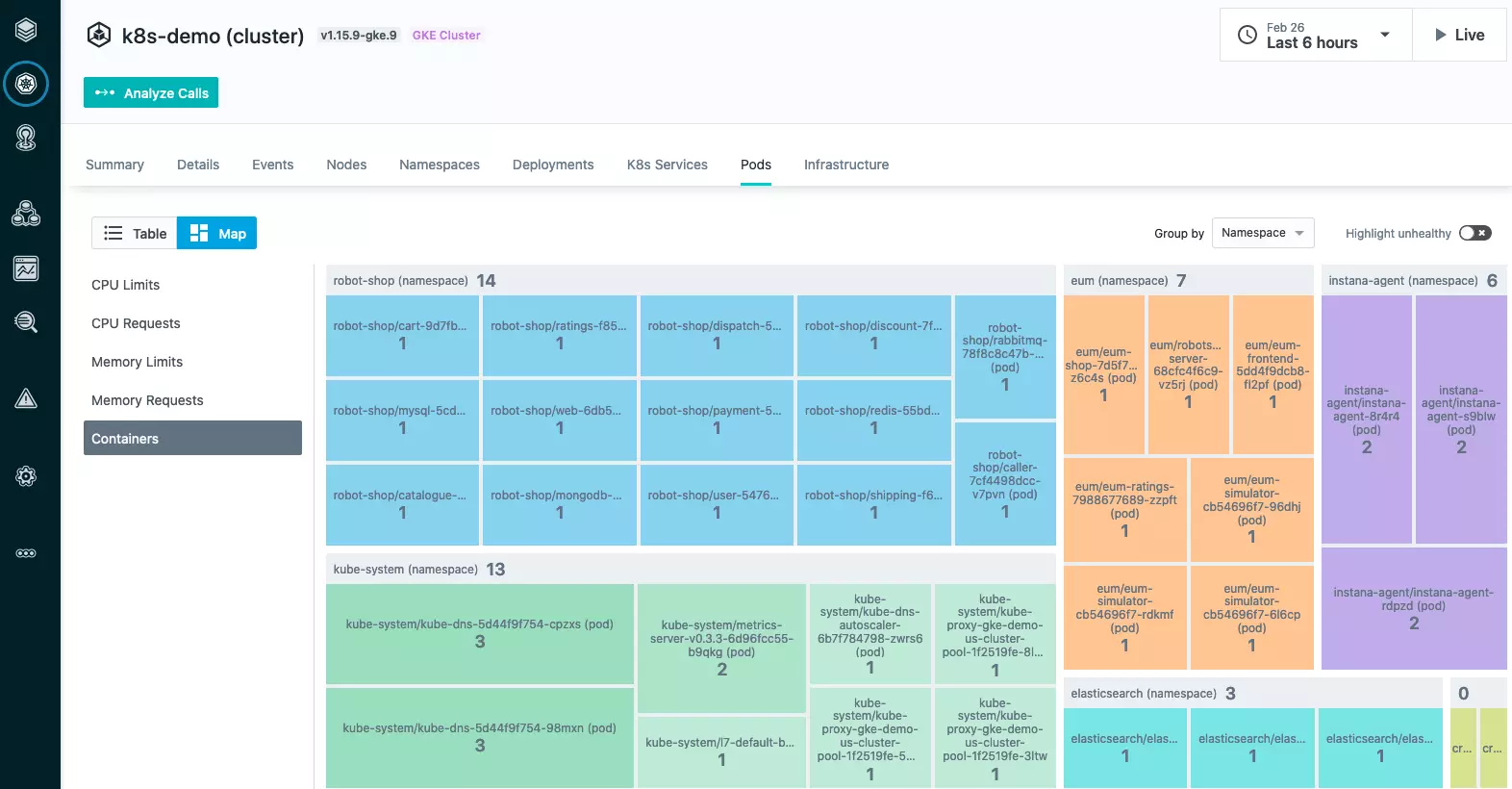
Instana’s K8s observability tool captures health and performance insights from your containers, nodes, apps, and pods. It also supports all K8s distributions, including RedShift’s OpenShift, and Amazon Elastic Kubernetes Service (EKS), and Rancher. It also automatically discovers your K8s services and enables real-time correlation and updates.
7. Sematext – Agent-based Kubernetes observability
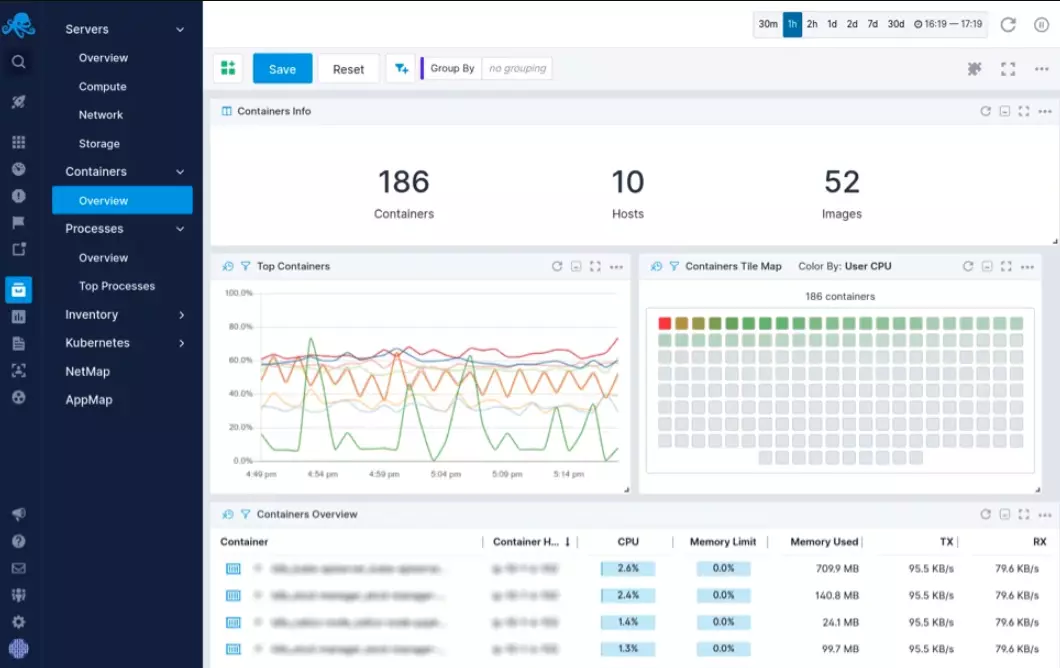
Sematext runs as a DaemonSet on K8s to capture, transform, and make sense of your Kubernetes environment. It uses container and host logs, metrics, and events for that. It derives the data from multiple sources, including infrastructure, apps, nodes, pods, services, and third-party integrations.
8. Pixie – eBPF-based K8s observability solution
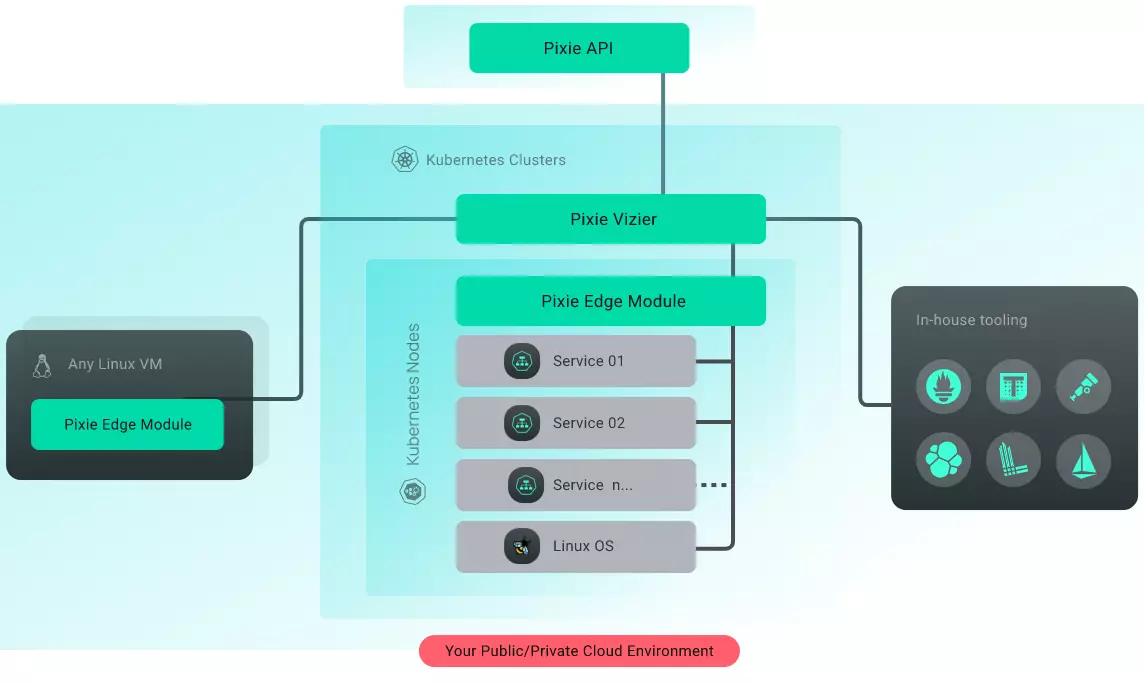
Pixie delivers a lightweight tool for observing Kubernetes metrics, events, traces, and logs. It uses eBPF ingestors and probes for that. Pixie also runs entirely in Kubernetes, minimizing complexity and bottlenecks of third-party integrations. Also, it enables you to use custom scripts to debug your K8s bugs as code.
9. New Relic integration with Pixie for Kubernetes observability
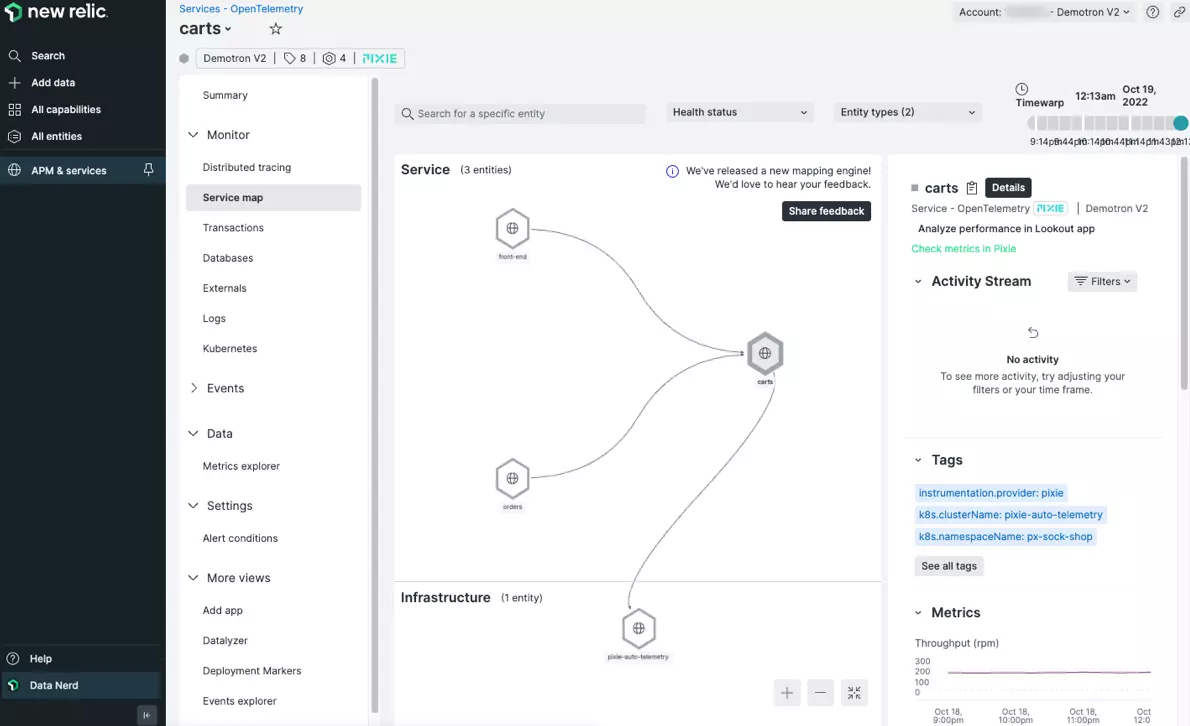
With this combo, New Relic’s full-stack Kubernetes monitoring service works in tandem with Pixie’s eBPF-based observability approach.
New Relic adds premium support, long-term Pixie telemetry retention, incident correlation, and smart alerting. Pixie contributes advanced capabilities like increasing visibility into unsampled requests and service-level metrics.
Kubernetes Observability Best Practices: What To Consider
Here is the thing. Some K8s observability tools, like cAdvisor and Heapster, deploy and monitor running applications from within a Kubernetes environment. If a cluster fails, their monitoring ability will also fail, which is not what you want.
So, unless your system has failover capability, you’ll want to log application data outside the cluster.
Here are more Kubernetes observability best practices to consider:
- Keep track of all the key components in Kubernetes, including pods, nodes, clusters, deployments, and services.
- Always use metrics, logs, and event traces together; they are the three pillars of observability.
- Automate Kubernetes observability with a robust tool to ease your work so you can collect accurate, real-time, and actionable insights.
- Avoid relying on managed Kubernetes services such as GKE, AKS, and EKS for all your observability work. You might not get the insights that matter most to your particular business from them.
- Getting a true picture of your Kubernetes deployment’s health and performance requires relating your findings to what else is going on (context).
- Use observability proactively to identify, understand, and resolve potential problems before they escalate into costly issues.
These are just some of the crucial best practices to always keep in mind.
Now, if viewing, understanding, and controlling your Kubernetes costs is important to you, here’s some news.
Achieve Better Kubernetes Cost Observability With CloudZero
Most conventional cost tools only show total and average Kubernetes costs – without highlighting who, what, and why your Kubernetes spend is changing.
With CloudZero, you can zoom in and out of K8s cost data to get a clear picture of how much you’re spending on specific services, pods, clusters, customers, deployments, etc. CloudZero’s observability approach also lets you collect unknown unknowns like costs of untagged, untaggable, and multi-tenant resources — automatically.
But don’t just take our word for it.  .
.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



