
At CloudZero, we drink deeply of our own champagne. We consider ourselves customer zero, and use our product to its maximum potential, to reduce wasteful spending and improve our unit economics. We even use our software to drive meaningful board discussions (with help from a slide template you can download here).
The nice thing about drinking our own champagne is that, after we do, we end up with more champagne than we started with — in this case, $470,000 that we would have spent needlessly on the cloud.
Here’s how our engineers went beyond commitment-based optimizations to save $470,000 a year.
AWS Lambda: $400,000
Provider: AWS
Resource: Lambda
Savings: $400,000 (annualized)
How: Migrated the Lambda functions responsible for file processing in our data ingestion pipeline from Pandas to Polars
The backbone of CloudZero’s value is ingesting, analyzing, and organizing — then driving meaningful savings insights. Cloud vendors and SaaS providers export a lot of data; the more efficiently we ingest and organize it, the more efficiently we deliver value to our customers.
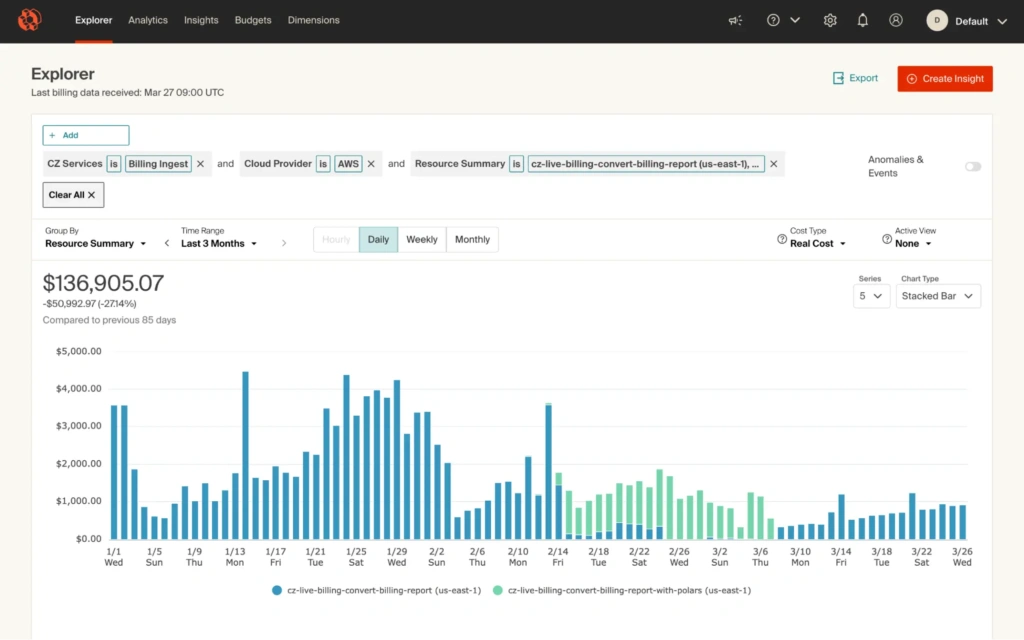
The engineering team responsible for our ingestion process recently identified performance issues with its Lambda. The underlying code used a Python-based file processing library (Pandas), which took up too much memory to perform efficiently. They chose to migrate the Lambda function responsible for file processing in the data ingestion pipeline to a faster, more efficient file processing library (Polars), anticipating that the latter would be more performant.
(Transparently, when this engineering team was explaining this to me, I had no idea why we were talking about bears. Personally, my life experiences have centered more around black bears and grizzlies.)
It was, and it also resulted in a significant cost reduction. Comparing our Lambda costs from a month before the change to a month after it, they calculated a ~$34,000 per month reduction, projecting out to, conservatively, $400,000 per year — for more performant infrastructure.
Win-win.

Snowflake: $70,000
Provider: Snowflake
Savings: $70,000 (annualized)
How: Re-architected our method of storing and surfacing resource tabs in Snowflake
As SaaS companies scale, infrastructure often becomes less performant. It’s the blessing and the curse of growth — you constantly need to interrogate your underlying infrastructure to balance performance and cost efficiency.
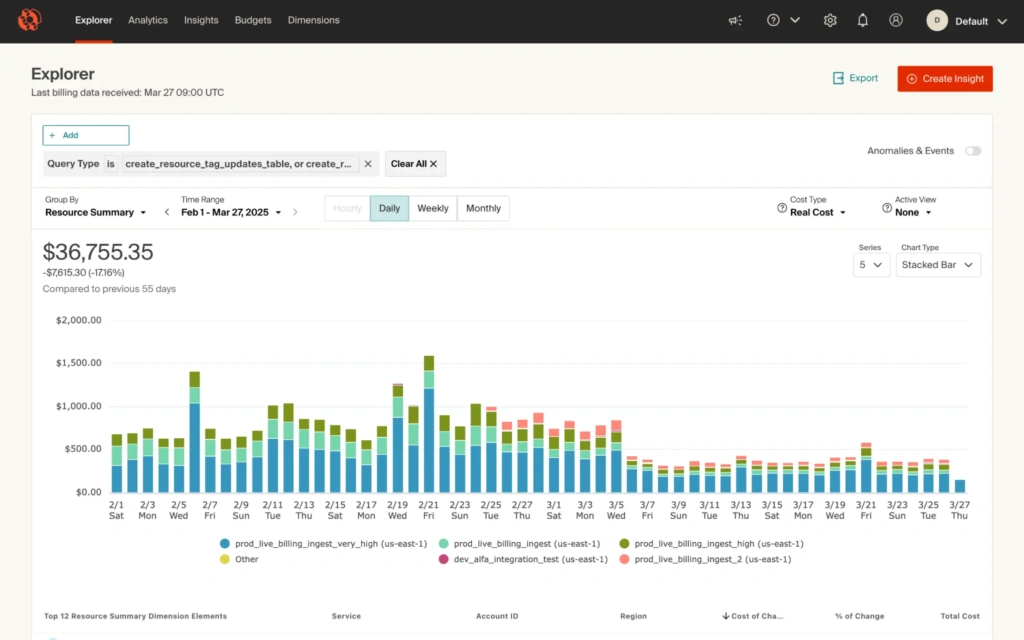
In addition to AWS, CloudZero leans heavily on Snowflake to ingest cost data. Amid our recent growth, we noticed a technical limitation in our Snowflake’s column solution that resulted in a suboptimal tag visibility experience for end-users.
So, the same engineering team re-architected the way we store and surface resource tags to address this deficiency. This nipped the visibility problems in the bud, made the data ingestion process more effective, and, happily, reduced our costs by about $70,000 per year.
More Performant, More Cost-Efficient, Better Customer Experience
The overarching lesson here is that building more efficient applications delivers a better customer experience and strengthens our unit economics. More performant solutions run faster, and, assuming you’re not using brute force to make those changes, things that run faster cost less. Well-written code = performant, cost-efficient code = better user experience.
Best of all, I didn’t ask my team to do any of this. They made these decisions because, with the visibility and insights they got from CloudZero, they were the clear best choices to make. That’s what happens when you arm your engineers with clean, relevant data.
Today’s most successful cloud-driven companies win because they can move extremely fast without ever pumping the brakes. How? By equipping their engineers with the right data to make cost-conscious decisions while they build. When your engineering team can quickly pivot to more performant, cost-efficient infrastructure, you accelerate innovation and stay ahead of the competition.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



