

Data drives decisions forward. Every insight leads to action. A 2024 Gartner report revealed that organizations utilizing analytics and AI are better positioned to manage complexity, build trust in data, and empower their teams.
This underscores the critical role of data intelligence. It involves collecting and analyzing data to uncover patterns and trends that help businesses take action. As a result, they can make informed decisions, optimize performance, and gain a competitive edge.
Yet, to unlock the full potential of data intelligence at scale, a robust platform is needed to manage and analyze data. One such platform is Databricks, a powerful tool widely used today. However, it might not be the perfect fit for every business. Why?
Read our guide below to discover Databricks alternatives and see how they compare.
But first…
What Is Databricks?
Databricks is a data lakehouse, a data platform that unifies the functions of a data lake with those of a data warehouse. While a data warehouse is designed for structured data, a data lake is meant for unstructured, semi-structured, and structured data.
That also means Databricks combines data processing, Big Data analytics, and data intelligence into one platform. In turn, your data scientists, analysts, and engineers can work together and faster from the same platform.
Yet, with all these strengths, Databricks may still not suit every organization’s needs.

Why Consider Databricks Alternatives?
First off, Databricks is a complex platform with a considerable learning curve. Mastering it isn’t always smooth, especially for smaller organizations or those with limited technical expertise or resources.
Databricks also present challenges in maintaining control over data processing. For some organizations, having granular control over their data processing environment is non-negotiable. In such cases, the extent of control provided by Databricks may not meet their precise requirements.
In addition, Databricks’ robust capabilities also come at a high price tag for a few reasons. Cloud infrastructure on cloud platforms can escalate costs. Enterprise licensing fees are also high. Processing large amounts of data and performing real-time analytics requires significant computing power, driving up costs further. Hiring skilled data scientists and engineers to manage the platform adds to operational costs.
These factors make Databricks an expensive data intelligence solution for many businesses, especially small-medium sizes.
However, if you really like Databricks and cost is your organization’s only pressing concern, there’s a powerful solution for you.
Enter CloudZero
CloudZero is a cost intelligence platform that integrates with Databricks, enabling businesses to manage and optimize all Databricks costs in a single platform.
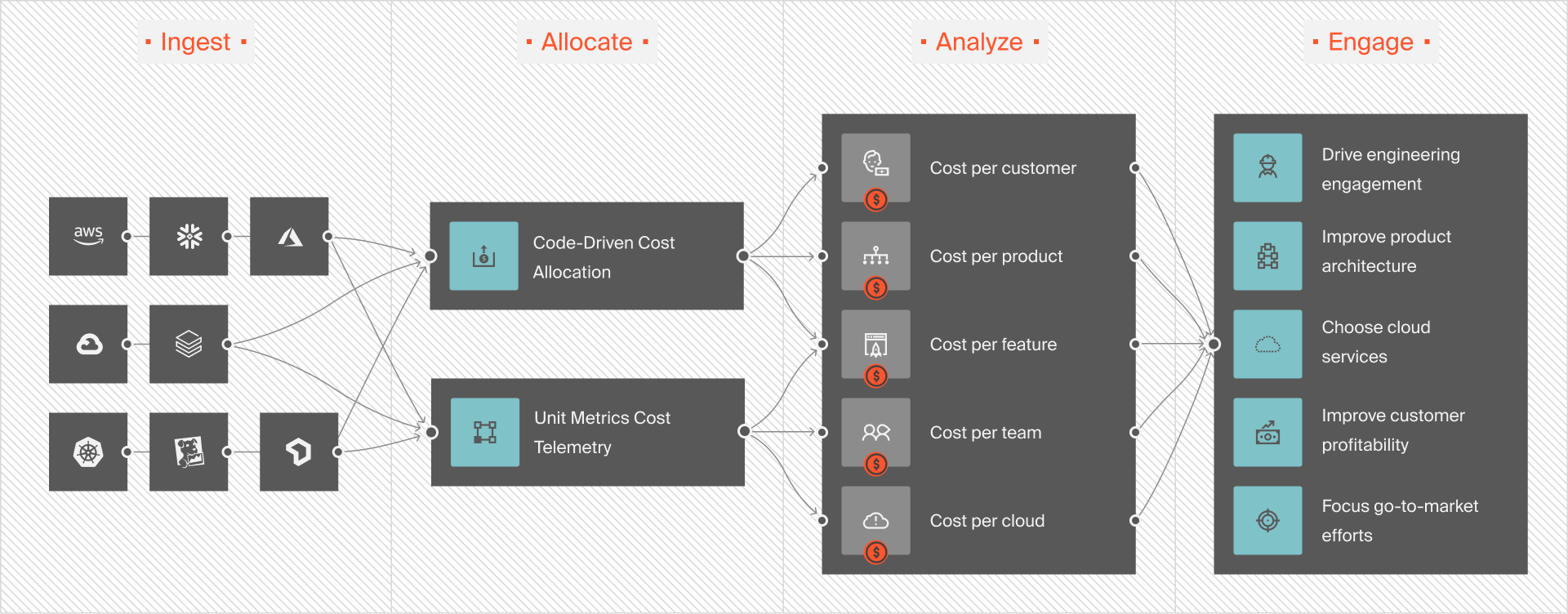
The CloudZero Databricks Adaptor enables you to ingest, allocate, analyze, and understand your Databricks costs like never before. Instead of viewing only total and average data costs, CloudZero empowers you to tell which specific people, products, and processes drive your Databricks charges.
This means you can then view your Databricks unit costs, such as cost per customer, team, or environment.
You can also understand and act on complete Databricks cost information (Databricks DBU pricing and the underlying infrastructure costs by AWS, Azure, or GCP) — all in one place.
Want to see how CloudZero can help you stay with Databricks without worrying about high costs?  to see how ambitious brands save millions on platforms like Databricks using CloudZero’s advanced analytics.
to see how ambitious brands save millions on platforms like Databricks using CloudZero’s advanced analytics.
However, if cost isn’t your concern, the market is rich with plenty of options for data intelligence and analytics platforms.
11 Databricks Alternatives Worth Considering
Consider the following.
1. SQL Server
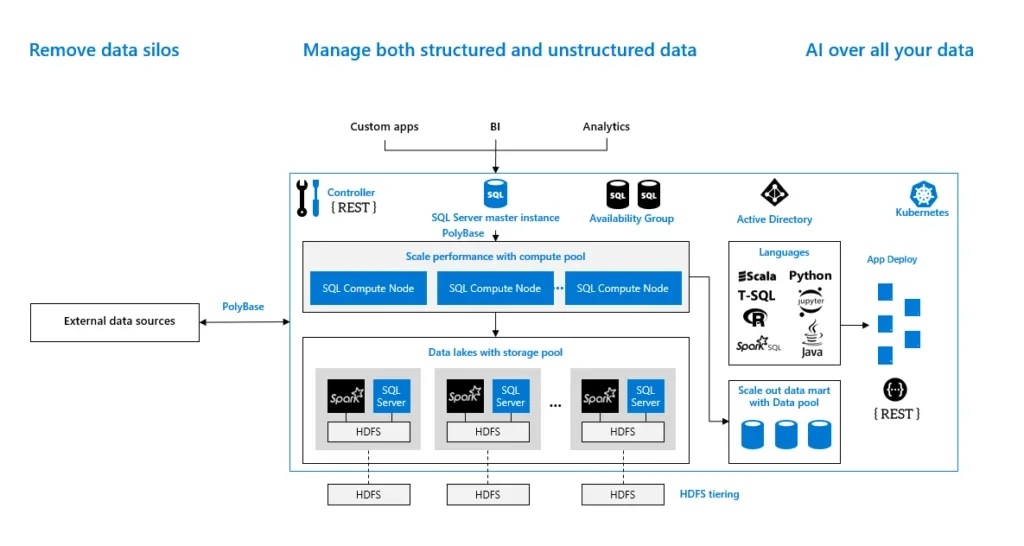
SQL Server is a relational database management system (RDBMS) by Microsoft. It uses Structured Query Language (SQL) to manage and query data. Its integration with data analytics tools such as Power BI and SQL Server Analysis Services (SSAS) makes it a compelling alternative to Databricks. It enables businesses to run complex queries, generate reports, and visualize data for intelligent insights.
With the support of its inbuilt tool, PolyBase, SQL Server can query both structured and unstructured data directly from data lakes without moving the data into SQL Server itself. This capability extends SQL Server’s functionality to external data sources such as Azure Data Lake, Hadoop, and Blob Storage.
SQL Server also features Big Data Clusters consisting of Linux containers managed by Kubernetes. This architecture enables it to integrate with Apache Spark for scalable analytics across large datasets.
2. Google BigQuery
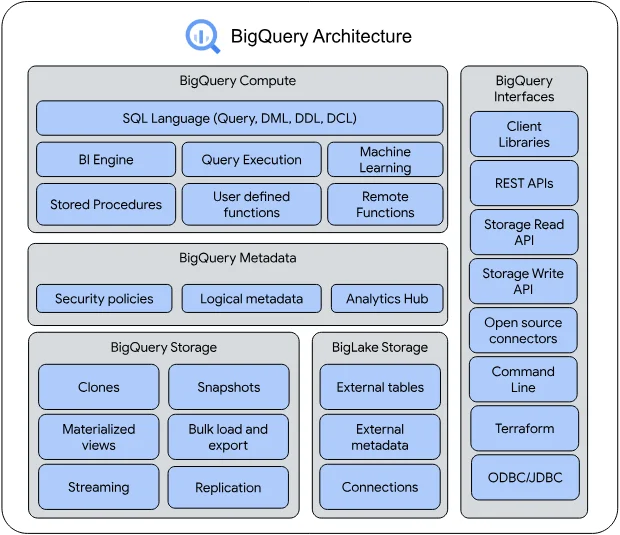
If you already use Google Cloud and most of its services, Google BigQuery will best fit you.
One of BigQuery’s biggest advantages over Databricks is its fully serverless architecture. It automatically manages infrastructure, scaling, and performance, simplifying use for analysts and data scientists. Databricks offers serverless features but relies on managed clusters for more complex tasks.
BigQuery also excels in real-time analytics, efficiently processing streaming data. In contrast, Databricks requires more configuration for real-time tasks, making it more challenging to implement compared to BigQuery’s simplicity.
For Google Cloud users, BigQuery offers a free tier of 1 TB of queries and 10 GB of monthly storage at no cost. There’s also a no-cost sandbox option, which enables users to explore BigQuery without providing a credit card or billing account.
3. Snowflake AI and Data Cloud

There’s a reason Snowflake is one of today’s most popular database platforms. And that mostly comes down to its patented, multi-cluster, shared data architecture, which separates storage from compute. This allows multiple virtual warehouses (clusters) to access the same data without slowing each other down. Clusters process queries independently, ensuring high performance under heavy workloads.
The Snowflake AI and Data Cloud extends these capabilities by integrating AI and machine learning. It empowers businesses to leverage large-scale analytics beyond traditional warehousing.
The choice between Snowflake and Databricks depends on your current and future business needs. In some cases, Databricks will lead with its data engineering and advanced analytics capabilities. However, Snowflake’s ease of use and native SQL support often suit businesses focused on data warehousing.
If you already use Snowflake, check out these Snowflake monitoring tools guide to help you manage its costs. We also offer a Snowflake pricing guide to help you understand its pricing structure and how to optimize it.
4. Oracle Database

Oracle Database (OracleDB) was the first commercially available database that used SQL, marking the beginning of the RDBMS era. It stores, manages, and retrieves large volumes of data in a structured manner.
Its built-in features, Oracle Real Application Clusters (RAC) and Data Guard ensure the database remains available during hardware failures or disasters. Oracle Autonomous Database uses machine learning for automation tasks. It also features robust security features, including encryption, auditing, and access control.
Oracle Database supports multitenancy through the Oracle Multitenant architecture. This allows multiple databases, known as pluggable databases (PDBs), to run within a single container database (CDB), optimizing resource management. Databricks also supports multitenancy but in a different way. It enables multiple users to share infrastructure through its E2 architecture, which provides logical multitenancy with data isolation.
However, unlike Oracle, Databricks depends on cloud infrastructure for scaling and resource management.
5. MongoDB
MongoDB is a NoSQL database. Unlike traditional relational databases that use tables, MongoDB stores data in JSON-like documents (BSON). This enables flexible and dynamic schema design, making MongoDB ideal for applications that need rapid data retrieval and management.
MongoDB supports horizontal scaling, which enables you to distribute data across multiple servers (sharding). This further strengthens its capability for handling Big Data. In contrast, Databricks scales by adding compute resources to process large datasets in parallel. This makes it more suitable for complex data processing tasks rather than serving as a primary database.
If you’re already using MongoDB and find its pricing complex, here is a detailed breakdown of MongoDB pricing that could help you understand the costs better. If, however, cost isn’t your concern and you’re looking for alternatives, here are MongoDB alternatives for NoSQL and SQL that you might want to consider.
6. Teradata Vantage
With its strong SQL capabilities, excellent workload management, and support for temporal tables, Teradata Vantage is a formidable player in enterprise analytics and data processing.
Its unified analytics platform integrates data lakes, data warehouses, and analytics. It enables businesses to handle a variety of data types and sources on a single platform, streamlining their data management processes.
Teradata Vantage offers scalability and performance, with high concurrency and parallel processing capabilities enabling it to manage large-scale data efficiently. Additionally, it supports hybrid and multi-cloud environments. This provides flexibility for businesses that operate across AWS, Azure, and Google Cloud.
Teradata Vantage also excels in AI, machine learning, and MLOps, featuring over 140 data science algorithms. These capabilities help train models on large datasets while automating tasks like model drift detection and rebuilding.
However, compared to Databricks, Teradata Vantage may have some significant management and cost considerations to weigh.
7. Qubole
Qubole is an open data lake platform. It is a notable alternative to Databricks, especially for cloud-based data platforms, AI, machine learning, and data analytics. It offers significant flexibility and customization options for its users. This aspect is particularly useful for businesses that require tailored data management solutions.
Qubole collaborates with other platforms to support data blending, visualizations, and high-volume data processing. It also offers capabilities like automated data ingestion, secure data sharing, and scalable analytics.
While Qubole delivers solid performance with high workloads and valuable data insights, it may slightly lag behind Databricks in overall performance metrics.
8. Amazon Redshift
If your organization heavily relies on AWS, Amazon Redshift is where to start. Its suitability as a Databricks alternative lies in its distinctive focus on running traditional SQL queries. It is tailored for businesses that store large amounts of structured data.
It integrates with BI tools like Tableau or Looker, which are also commonly used for reporting. It works with most ETL (Extract, Transform, Load) tools such as AWS Glue, Talend, and Informatica, which help clean, prepare, and move data from other sources into Redshift.
Redshift supports parallel uploads from Amazon S3, EMR (Elastic MapReduce), and Amazon DynamoDB using its massively parallel processing (MPP) architecture. This ensures fast data uploads from these sources.
One more thing. Amazon Redshift is a PaaS, and Databricks is a SaaS. While SaaS requires less management, configurations also come at a higher cost than PaaS platforms. This makes Amazon Redshift a cost-effective Databrick alternative.
However, Amazon Redshift is limited to AWS, whereas Databricks works across all major cloud platforms.
Check out this Amazon Redshift guide to learn more about its use cases, benefits, pricing, and how to optimize its costs with CloudZero.
9. Dbt
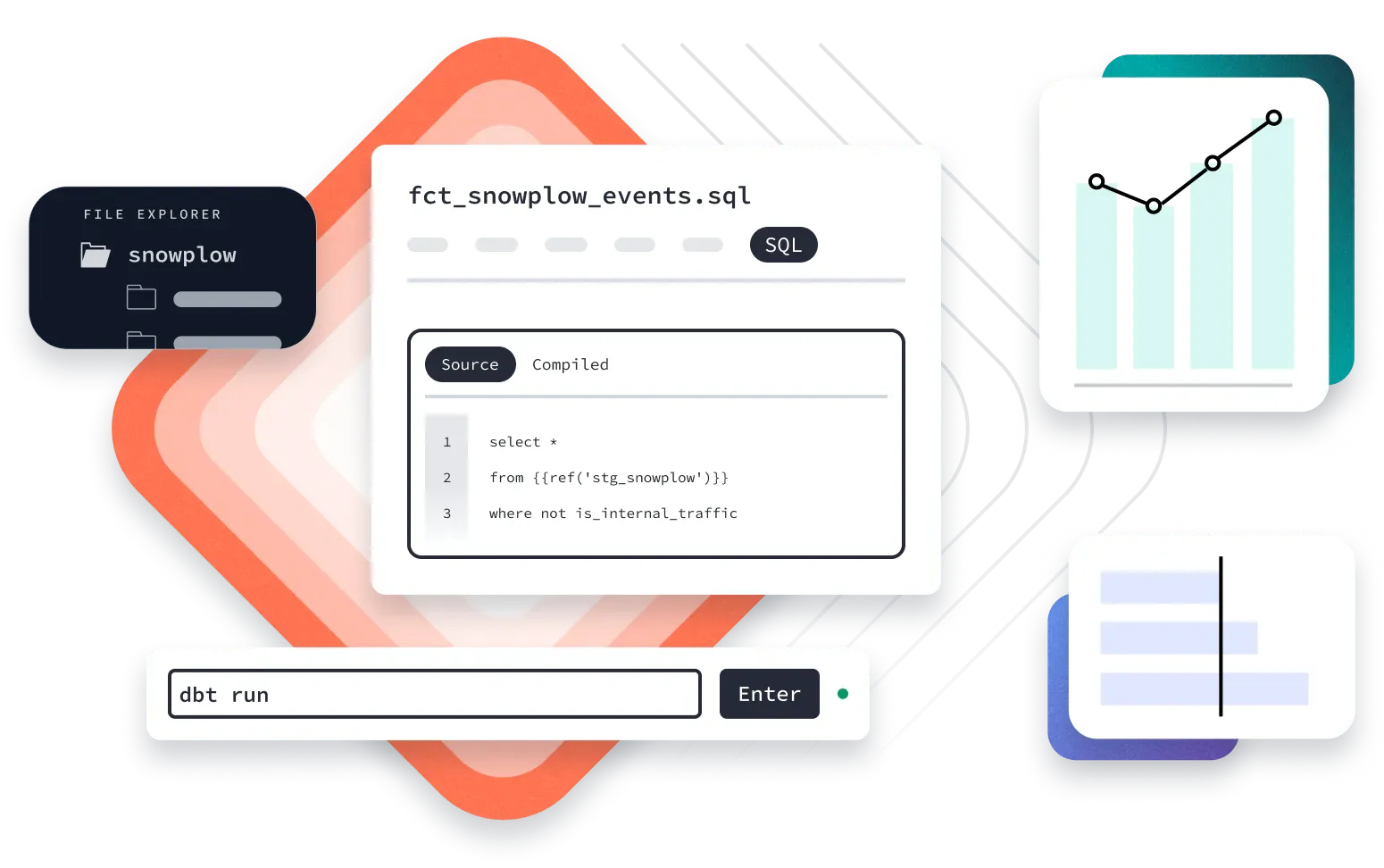
Dbt (Data Build Tool) is an open-source command-line tool. It helps data analysts and engineers transform and manage data inside their warehouses. While not entirely an ETL tool, Dbt focuses on the T in ETL (Extract, Transform, Load). This enables users to transform raw data into models by writing SQL queries, which are then version-controlled and documented.
It integrates with Databricks, Snowflake, Amazon Redshift, and other platforms to simplify data transformations that are difficult to implement with SQL.
10. Cloudera
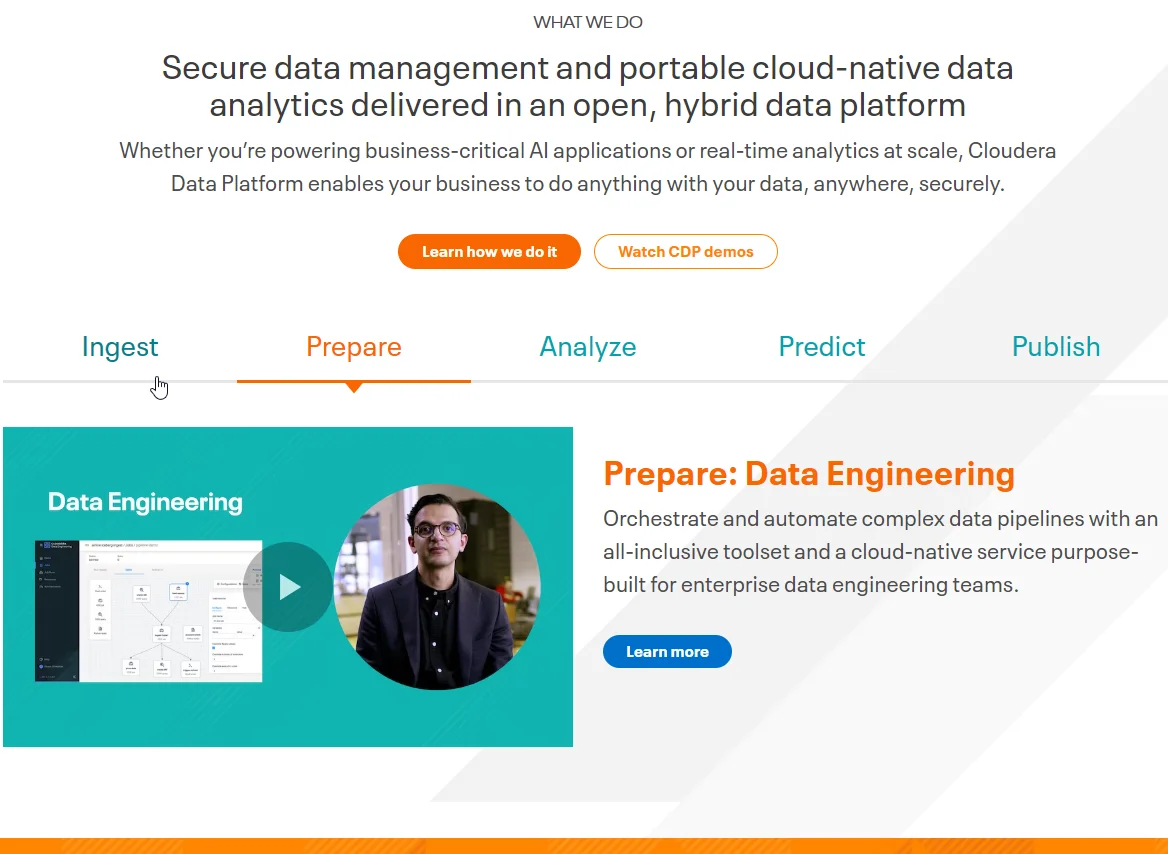
Cloudera is an ideal alternative to Databricks if you want an Apache Hadoop-based solution optimized to handle large-scale data across distributed computing clusters.
The platfrom offers a comprehensive set of data management tools. The Cloudera DataFlow and Apache NiFi ingest data, while Apache Atlas supports end-to-end data lineage. The Cloudera Shared Data Experience (SDX) integrates Apache Atlas and Apache Ranger for data governance. The Cloudera Data Catalog helps organize and manage metadata.
It also integrates with analysis tools like Apache Hive for SQL-like querying and Apache Impala for high-performance analytics. With HDFS and MapReduce, Cloudera can manage massive datasets and parallelize computations effectively.
11. Alteryx
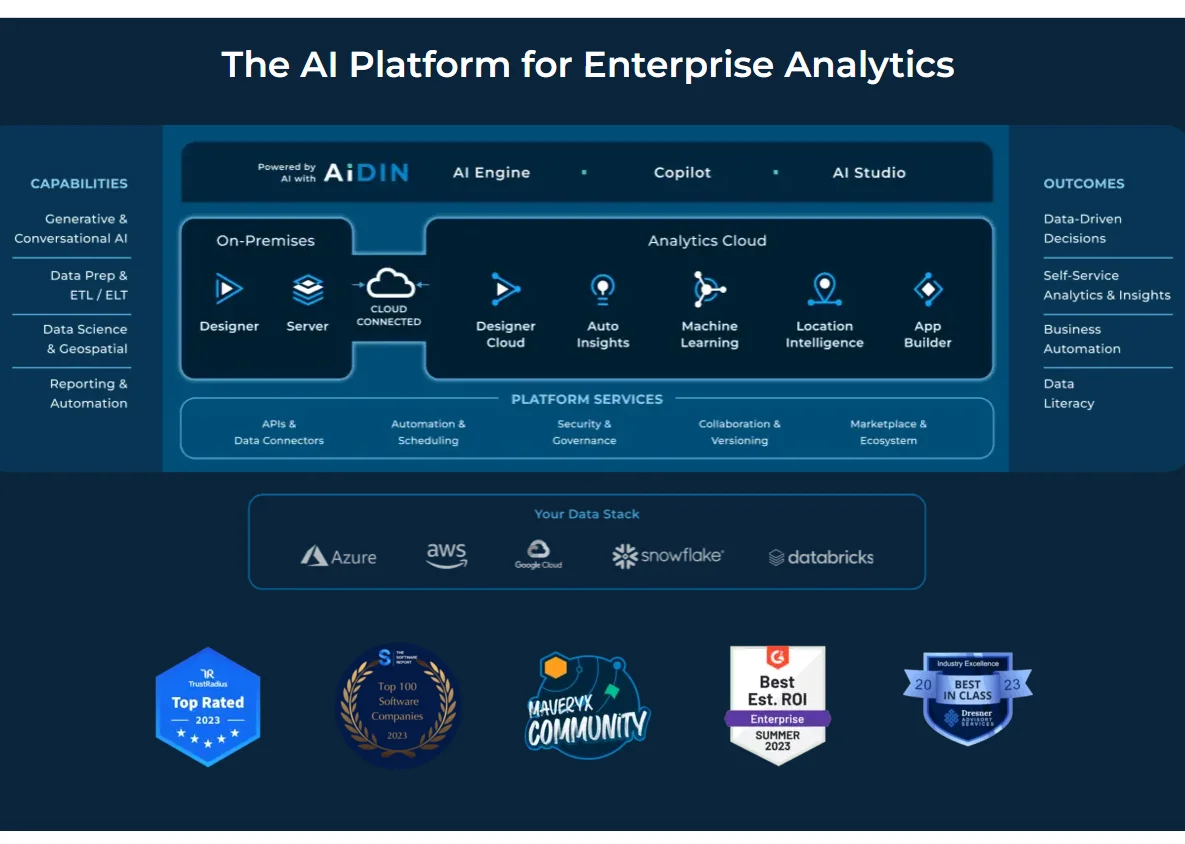
If you are looking for a versatile and user-friendly data analytics platform, consider Alteryx. Its other strengths as a viable alternative to Databricks are in data blending, cleansing, and advanced analytics.
Alteryx offers a powerful suite of features for data management and analytics. Its visual workflow designer allows users to build complex workflows through a drag-and-drop interface, eliminating the need for extensive coding.
The platform includes advanced capabilities for statistical analysis, predictive modeling, and spatial analytics. Its automation and scheduling features streamline repetitive tasks and workflows, boosting productivity.
It also integrates with multiple data sources, enabling smooth data processing across platforms. This makes it highly versatile for a wide range of analytic applications.
As we recommended earlier, be sure to assess each platform more in-depth, compare it with your data processing, analytics, and AI/ML goals, and make the choice that best suits your business needs.
Then Understand, Control, and Optimize Your Cloud Cost With CloudZero
With CloudZero, you’ll not only gain insight into the unit costs associated with your data, but you’ll also discover exactly where you can optimize usage and costs without sacrificing performance.
CloudZero achieves this by turning cloud cost data into hourly, granular, and instantly actionable insight. Consider cost per customer, team, environment, product feature, service, and other dimensions that align with your business operations.
CloudZero works where you do, too: AWS, Azure, and GCP, as well as Databricks, Kubernetes, MongoDB, Datadog, New Relic, Snowflake, and more. No separate views are required. You can view all of your cloud spending in a single dashboard and platform.
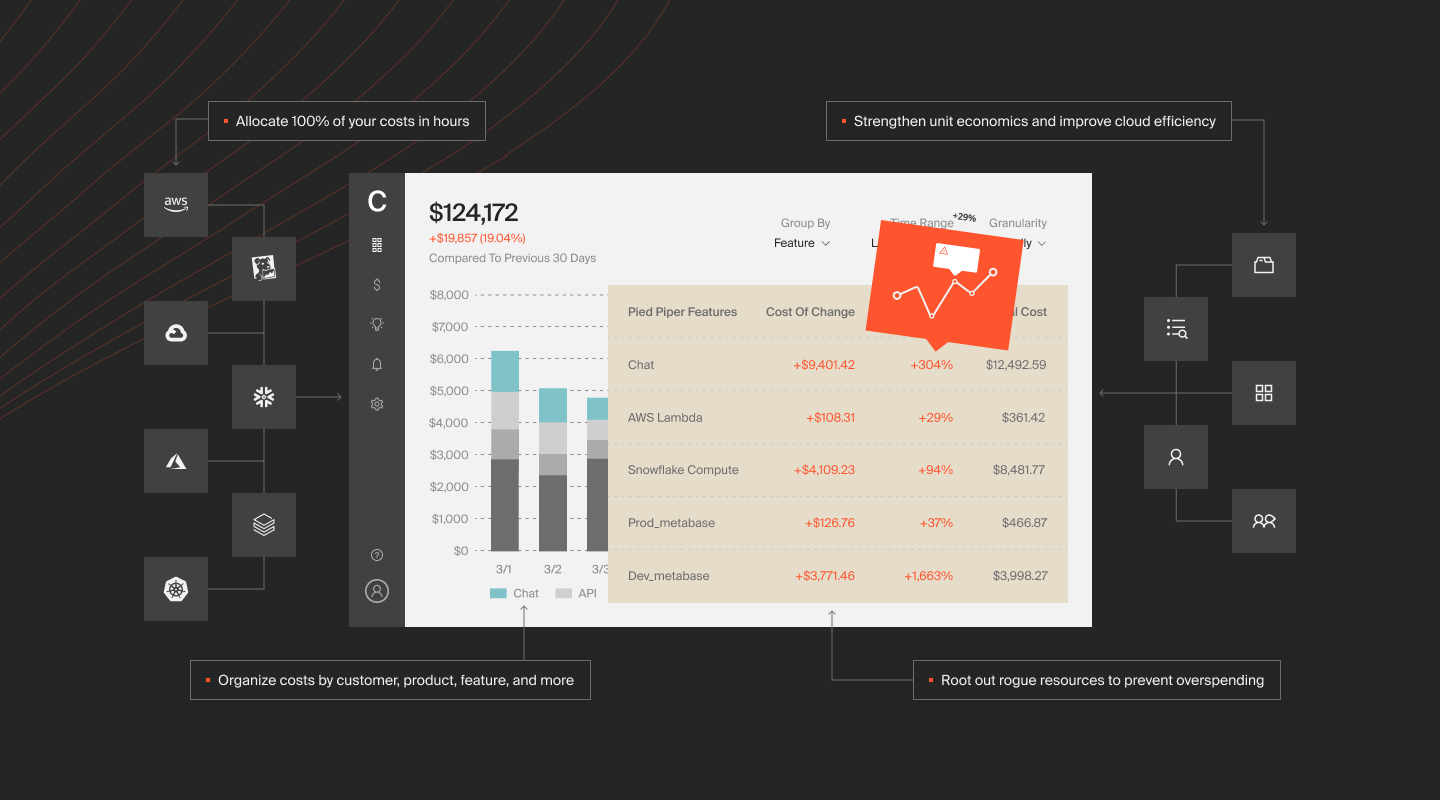
We’ll also send you timely, noise-free, and context-rich cost anomaly alerts to help you fix issues that could lead to overspending on data analytics, ML, and more.
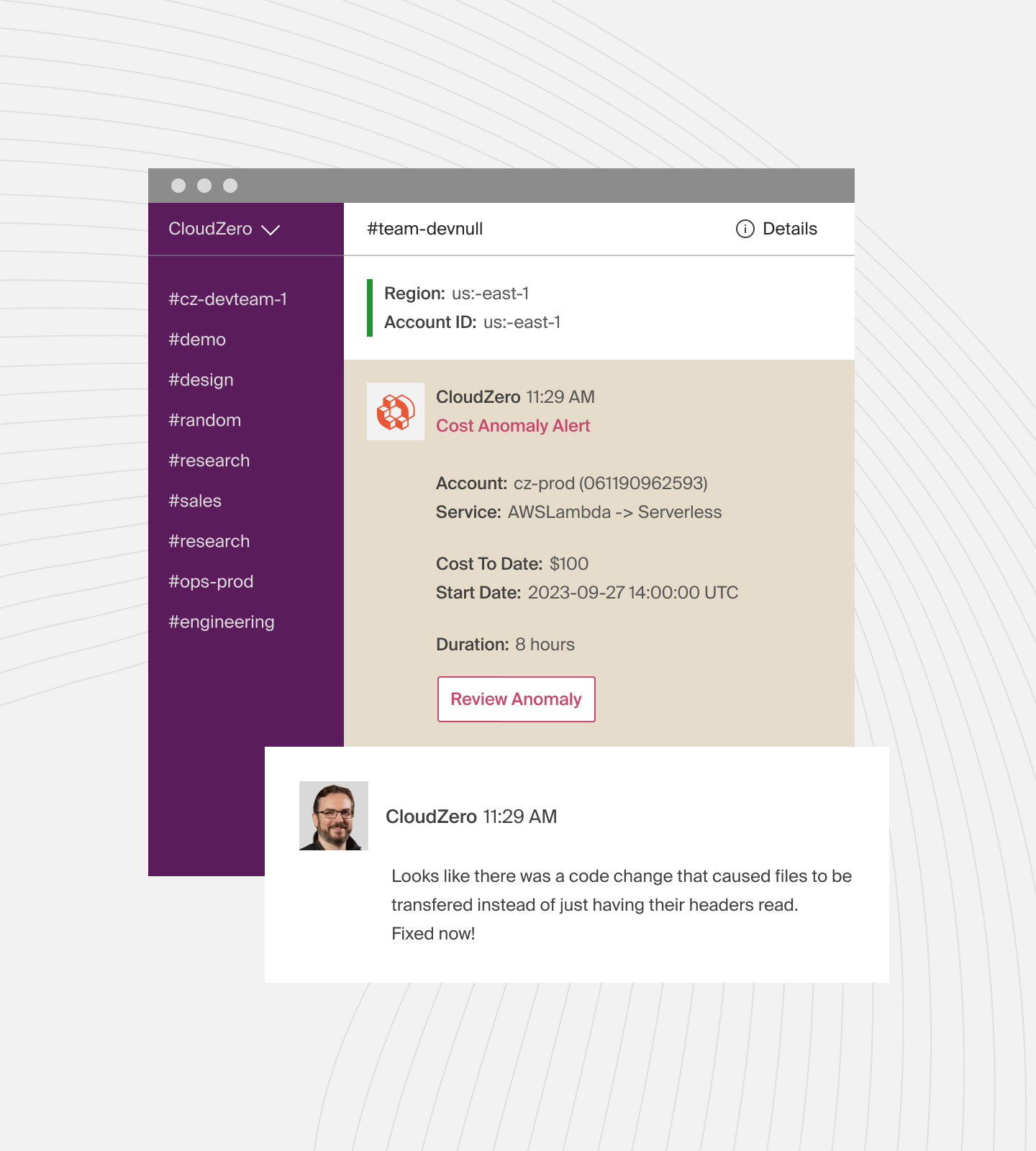
Ultimately, we have a Certified FinOps practitioner ready to help you make the most of CloudZero. and experience CloudZero in action now.


The Cloud Cost Playbook
The step-by-step guide to cost maturity



