
Also known as application performance monitoring (APM), application monitoring tools track and analyze application performance. They monitor application metrics such as CPU usage, response times, error rates, and uptime. The tools also offer real-time insights to identify issues, improve user experiences, and optimize resources.
But are APM tools really necessary?
Why You Need An Application Monitoring Tool
Application monitoring tools are crucial for several reasons.
- Performance and availability. APM tools help ensure applications run smoothly and are available when needed. They also detect anomalies and potential issues before they impact users. This reduces downtime and maintains a positive user experience.
- Scalability and cost optimization. Cloud environments are dynamic, and APM tools help manage this complexity by scaling resources as needed. They track resource usage and identify underutilized assets, which can help optimize costs by shutting down or reallocating resources during low usage periods. This ensures that the application operates without incurring unnecessary costs.
- Security and compliance. APM tools provide visibility into potential vulnerabilities, allowing organizations to take proactive measures to secure their applications. This is particularly important in cloud settings where infrastructure spans multiple environments, making centralized monitoring essential for maintaining security and compliance.
- Operational efficiency. The tools automate monitoring tasks, reducing the need for manual work and boosting efficiency. They also offer analytics and reports, helping teams spot trends and make data-driven decisions to improve application performance and reliability.
Report
Finance needs to prove AI’s return: CloudZero report
260 senior finance leaders (more than half CFOs) told us why the speed of seeing AI spend, not the size of it, separates who pulls ahead on AI from who gets burned.
Application Monitoring Tools For Different Use Cases
Here are some of the most common use cases for application performance monitoring.
- Response time monitoring. Tracks how long it takes for applications to respond to user requests.
- Uptime monitoring. Ensures the application is available and operational.
- Infrastructure monitoring. Monitors servers and hardware.
- Container monitoring. Tracks containerized application performance.
- Error rate monitoring. Monitors the frequency and types of errors occurring in the application.
- Resource usage monitoring. Measures CPU, memory, and other system resource usage.
- Transaction tracking. Follows specific transactions to identify bottlenecks.
- User experience monitoring. Analyzes user interactions and satisfaction.
- Log monitoring. Collects and analyzes logs for patterns and anomalies.
- Database performance monitoring. Tracks database queries and performance efficiency.
- Network performance monitoring. Measures network latency, throughput, and other network-related metrics.
- Security monitoring. Detects and addresses security threats within the application.
- DevOps support. Facilitates collaboration between DevOps teams for continuous integration, deployment, and monitoring.
Here are the best application monitoring tools to consider:
Full-Stack APM Platforms
These platforms provide end-to-end visibility across your entire application stack — from frontend user experience to backend infrastructure. They combine distributed tracing, metrics collection, log aggregation, and alerting into a single unified platform, making them the go-to choice for engineering teams managing complex, distributed architectures.
1. Datadog
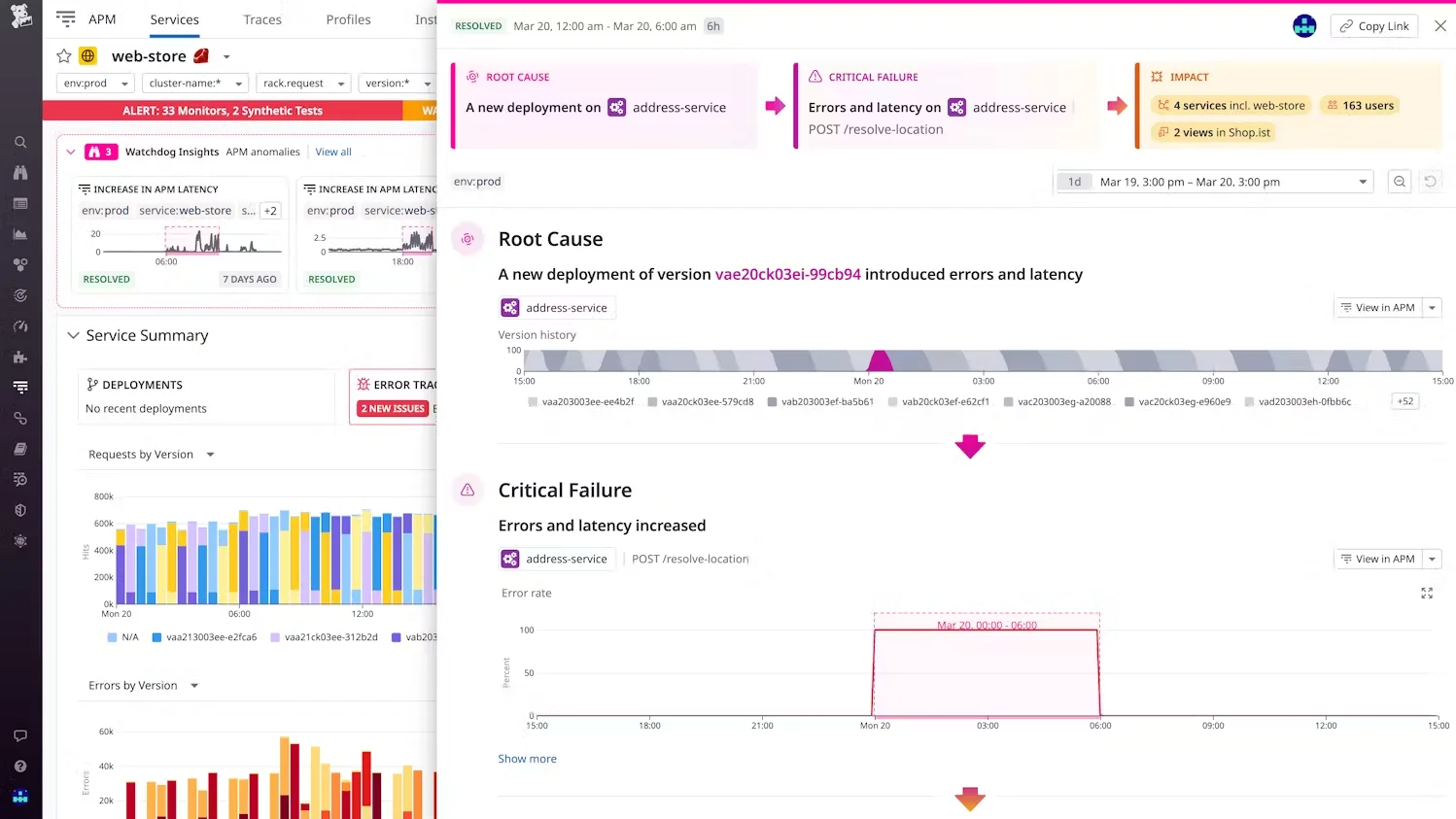
Datadog is a monitoring and analytics platform for infrastructure, applications, and logs. Its Application Performance Monitoring (APM) offers deep visibility into your applications’ performance and health. It utilizes AI-powered code-level distributed tracing to monitor interactions from browser and mobile applications to backend services and databases.
Key Datadog features include:
- Faster detection and resolution of root causes
- Real-time end-to-end tracing
- Intelligent alerts and anomaly detection
- Automatic deployment tracking
- Network performance monitoring
- Synthetic monitoring
- Integration with popular DevOps tools
Datadog offers a range of performance monitoring services that can make pricing complex. Check out our article on managing Datadog costs with CloudZero.
2. New Relic
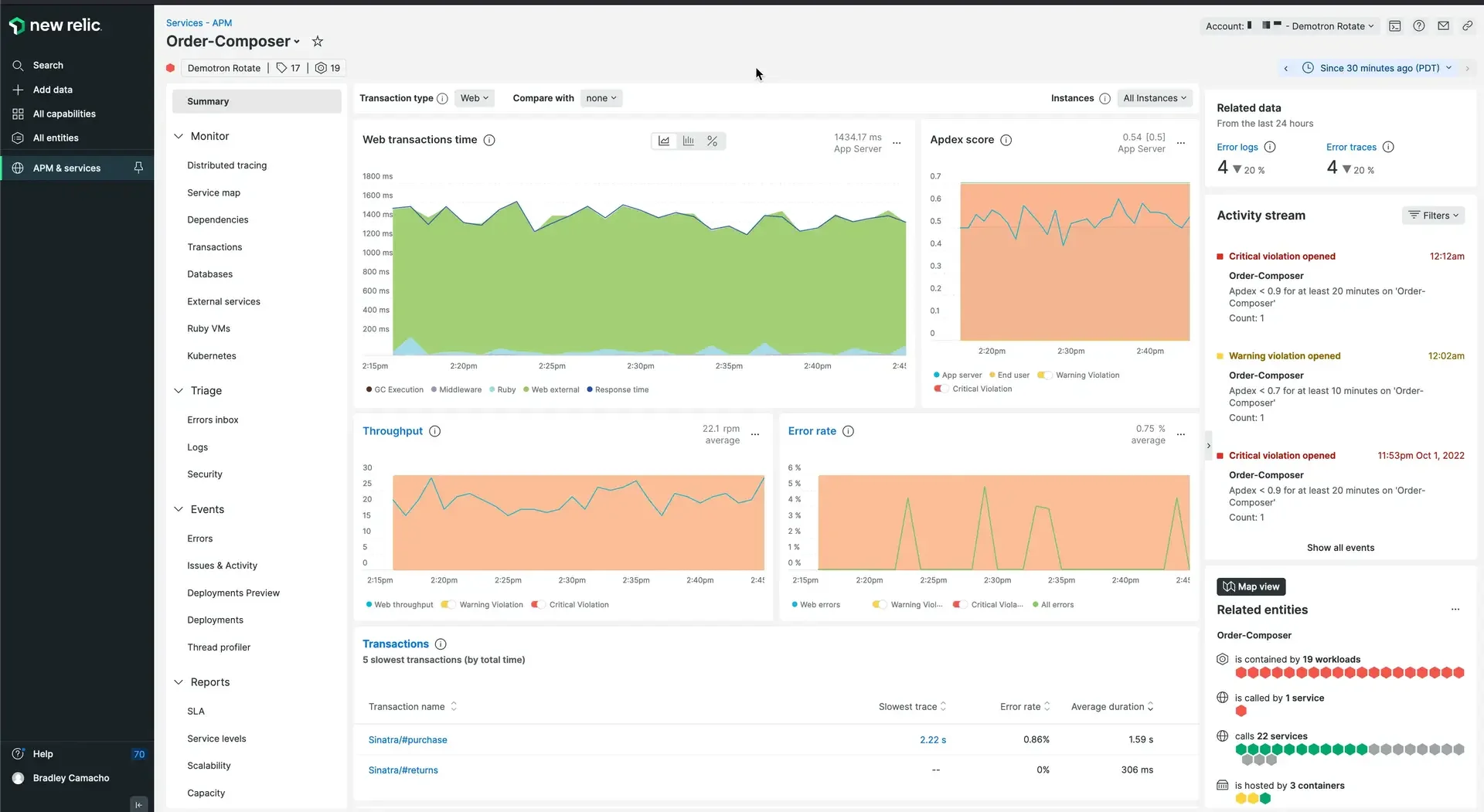
New Relic is an observability platform that helps developers and engineers monitor, debug, and improve their entire stack. Its code-level visibility provides detailed transaction data, including metrics, event data, transaction traces, SQL queries, and stack traces. This allows for quick identification and resolution of performance issues.
New Relic supports over 750 integrations with DevOps tools, cloud services, and infrastructure components.
Key New Relic features include:
- End-to-end tracing
- Supports real-user monitoring (RUM) and synthetic monitoring
- Optimizes resource usage
- Scalable architecture
- Monitors Kubernetes and microservices
- Serverless monitoring
- Log management
If you already use New Relic for observability and application monitoring and are looking for alternatives, consider these New Relic alternatives.
3. Dynatrace
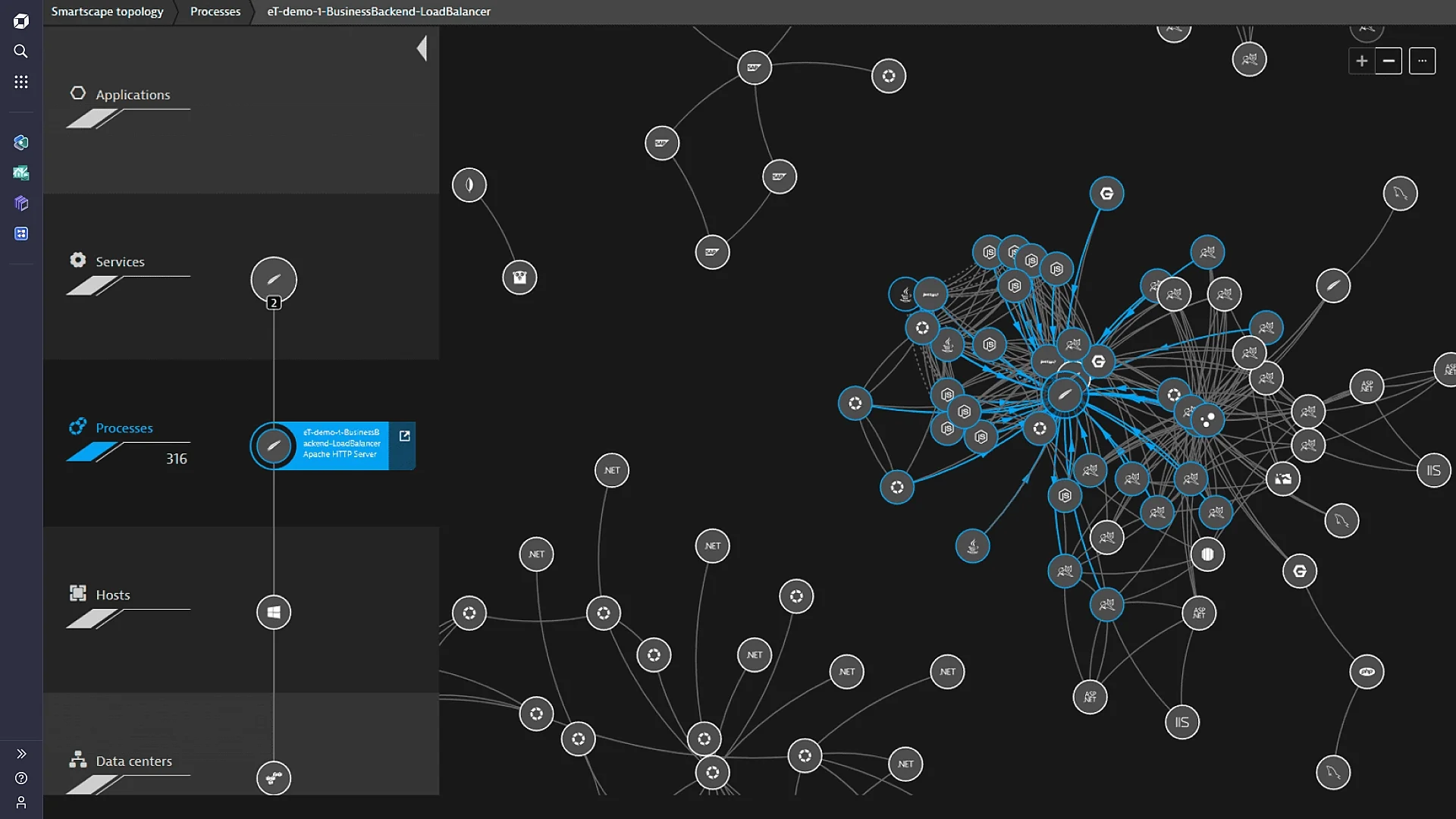
Dynatrace monitors infrastructure across on-premises, cloud, and hybrid environments. It offers insights into server performance, network health, virtualization, microservices, and containers. It also supports over 650 technologies, helping maintain optimal performance across the entire technology stack.
Key Dynatrace features include:
- Continuous auto-discovery and topology mapping
- Visual representation of application dependencies
- Integrated user-experience metrics
- Real user data and synthetic transaction monitoring
- Tracking of customer journeys end-to-end
- Database health metrics and SQL statement performance visibility
- Service-to-database dependency mapping
- AI-driven root cause analysis
4. AppDynamics
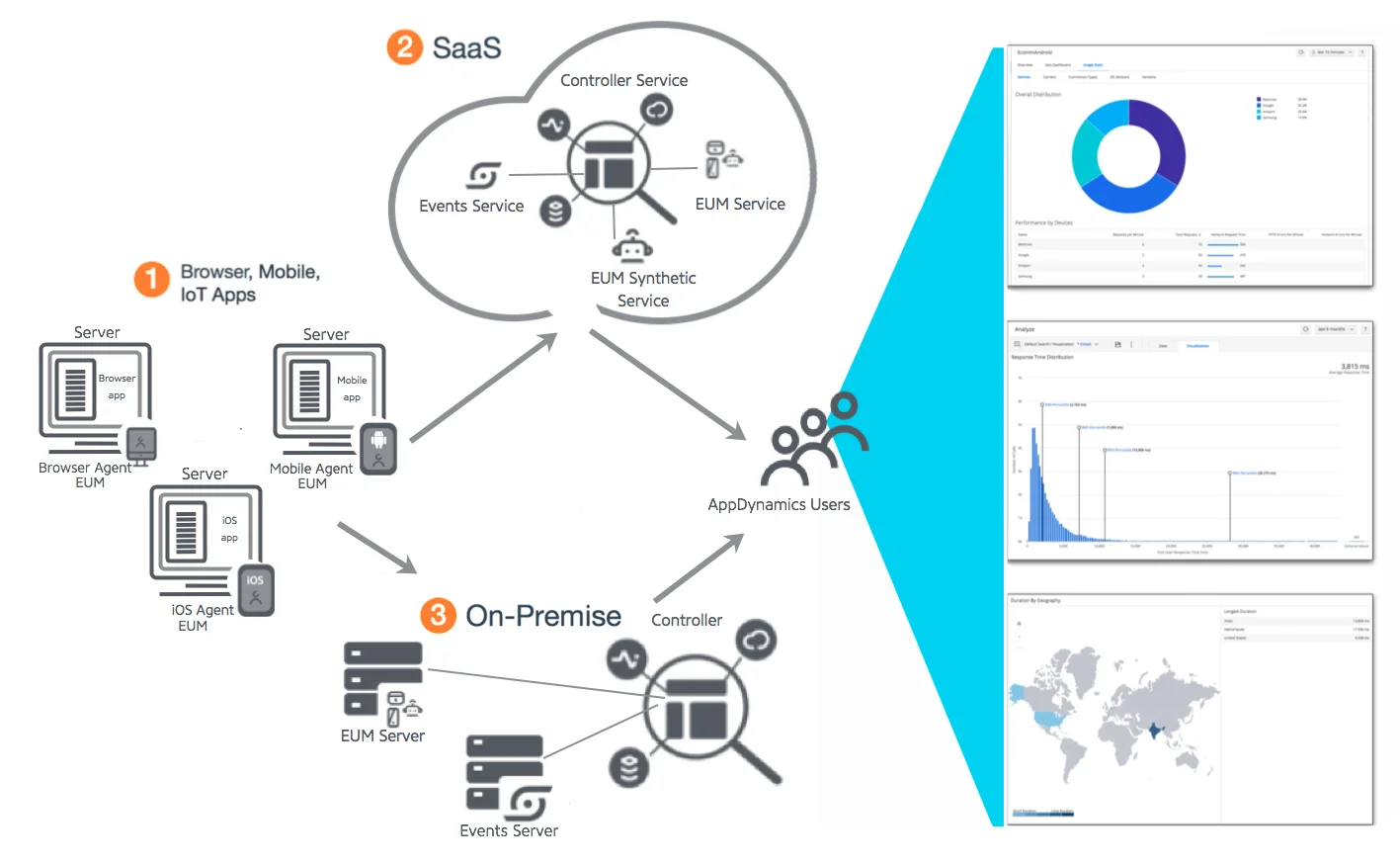
AppDynamics’ End User Monitoring (EUM) tracks web and mobile application performance. It includes Experience Journey Mapping to visualize user interactions and identify optimization opportunities. It also integrates with real-user monitoring (RUM) and synthetic monitoring to detect and resolve performance issues before they impact users.
Key AppDynamics features include:
- Real-time monitoring and diagnostics
- Integration with IT and DevOps tools
- Supports cloud-native, on-premises, and hybrid environments
- Visibility across all infrastructure layers
- Offers Business iQ to correlate application performance metrics with business outcomes
- Automatic discovery and mapping
5. Splunk Observability Cloud
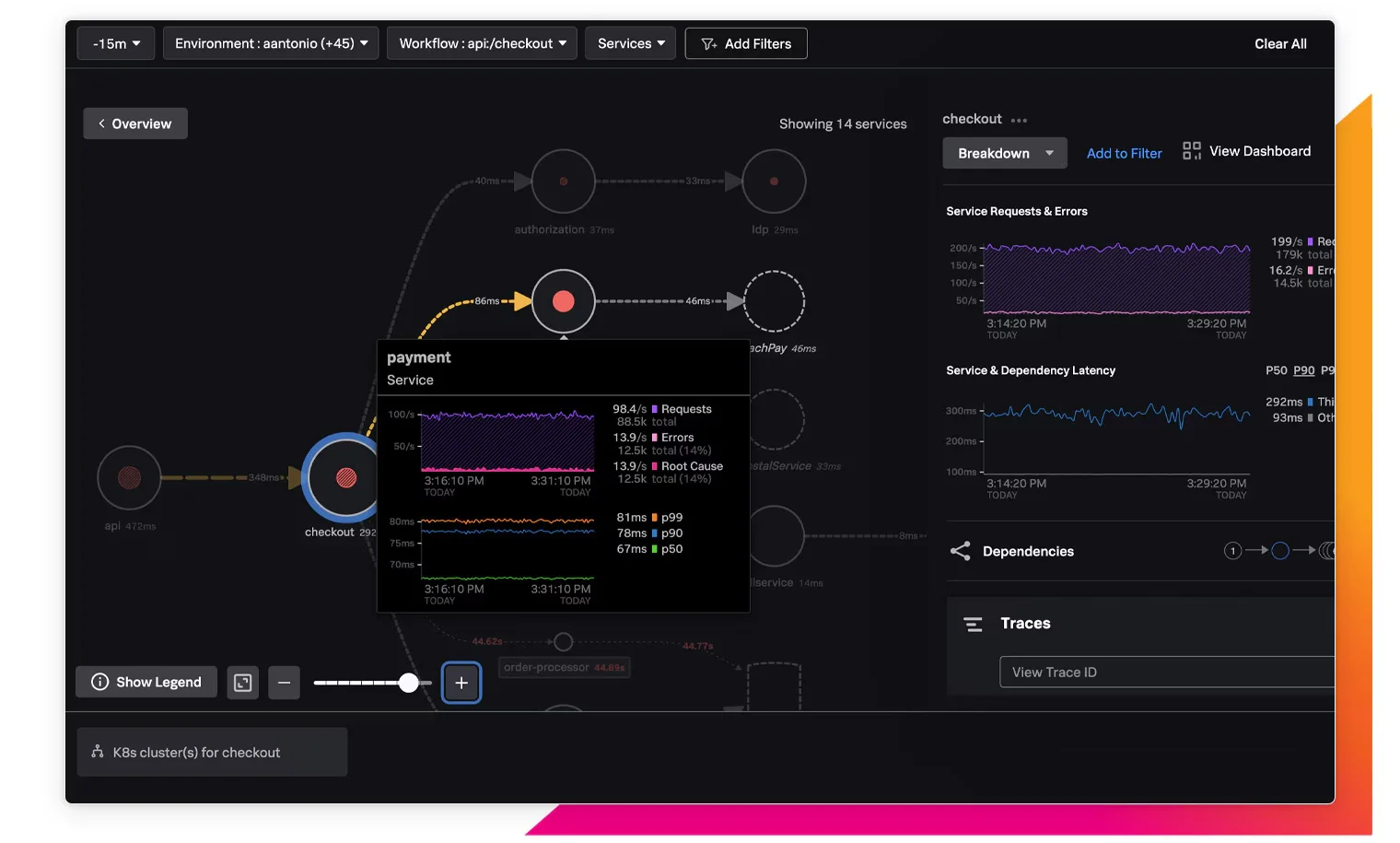
Splunk Observability Cloud (which now includes the former SignalFx capabilities) supports real-time visibility into application performance and security by collecting and analyzing data from various sources. It links security incidents to performance issues, offering a complete view of the IT environment.
Using AI and machine learning, Splunk automates threat detection and alerting. It ingests data from logs, metrics, and traces, ensuring end-to-end visibility for identifying and mitigating threats.
Key Splunk features include:
- NoSample™ architecture captures 100% of transaction traces without sampling
- OpenTelemetry-based instrumentation supports multiple programming languages
- AlwaysOn Code Profiling monitors CPU and memory usage for specific code
- Service Map visualizes services and their interactions
- Trace Analyzer stores and analyzes all traces for root cause identification
- Tag Spotlight analyzes service performance based on indexed span tags
- Business Workflows correlates related traces for monitoring transactions
- Built-in dashboards monitor service, endpoint, and system health
6. Instana
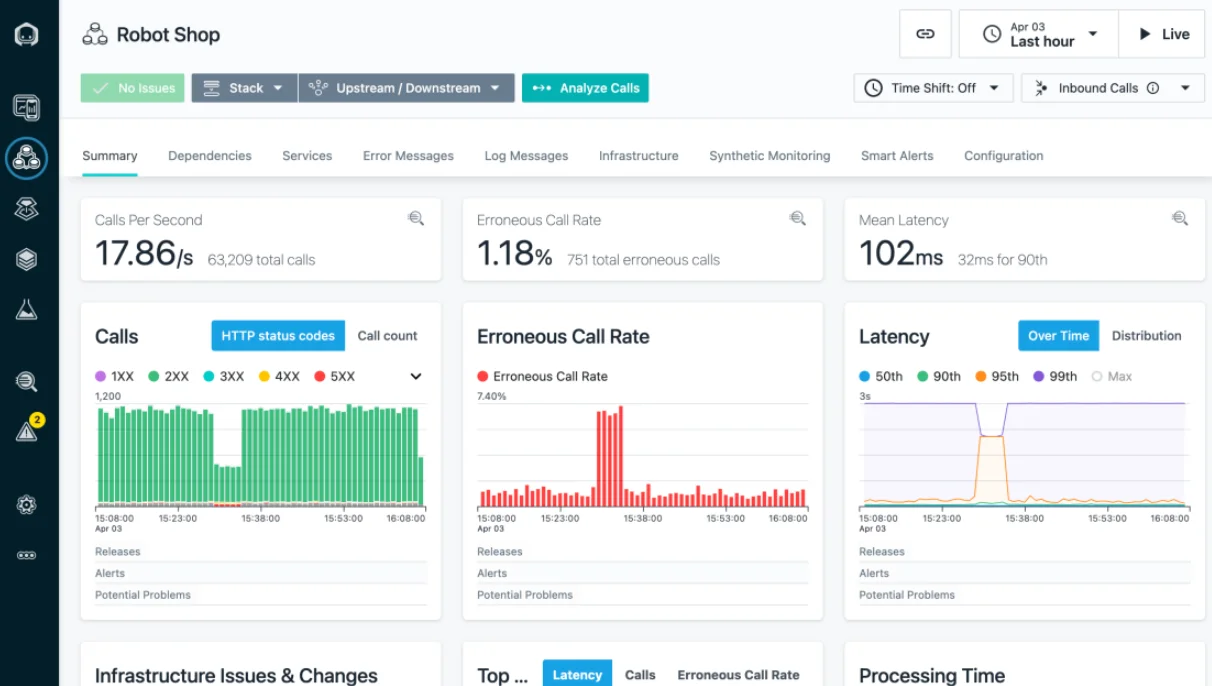
Part of IBM, Instana offers real-time visibility into servers, containers, and databases. It automatically uses AI-powered monitoring to discover and map applications, services, and infrastructure. It ensures precise tracking of performance and health across on-premise, cloud, and hybrid setups.
Instana agents collect detailed metrics every second, enabling rapid issue detection and resolution. The platform automates alerts and fixes, linking performance data and events to find root causes quickly.
Key Instana features include:
- Distributed tracing
- Smart alerts
- Service quality management
- Continuous deployment support
- Contextual insights
- Integration with DevOps tools
- Synthetic monitoring
Open-Source And Community-Driven Monitoring
Open-source monitoring tools give engineering teams full control over their observability stack — with no vendor lock-in, transparent pricing, and the ability to customize everything. These tools are often the foundation of monitoring stacks at startups and large enterprises alike, frequently combined with commercial platforms for specific capabilities.
7. Grafana
Grafana is the open-source standard for metrics visualization and dashboard building. It connects to virtually any data source — Prometheus, InfluxDB, Elasticsearch, CloudWatch, and dozens more — and lets teams build rich, customizable dashboards for infrastructure, application, and business metrics. Grafana Cloud extends the platform with managed Prometheus, Loki (logs), and Tempo (traces) for a complete observability stack without the operational overhead of self-hosting.
Key Grafana features include:
- Multi-data-source support with unified dashboards
- Highly customizable visualization panels
- Alerting with multi-channel notifications
- Grafana Loki for log aggregation
- Grafana Tempo for distributed tracing
- Plugin ecosystem for extending functionality
- Team-based access controls and annotations
8. Prometheus

Prometheus collects metrics from targets at set intervals and stores them as time series data. It uses PromQL for detailed analysis and adapts to infrastructure changes with dynamic target discovery. The multi-dimensional data model uses labels for flexible querying. Prometheus integrates with Grafana for custom dashboards and includes an alert manager for notifications based on thresholds. These features make Prometheus ideal for monitoring servers, databases, and cloud-native applications like Kubernetes.
Key Prometheus features include:
- Time series data storage with flexible querying via PromQL
- Automatically discovers targets, simplifying configuration
- Easily scalable
- Fully open source with a large community
9. Elastic APM
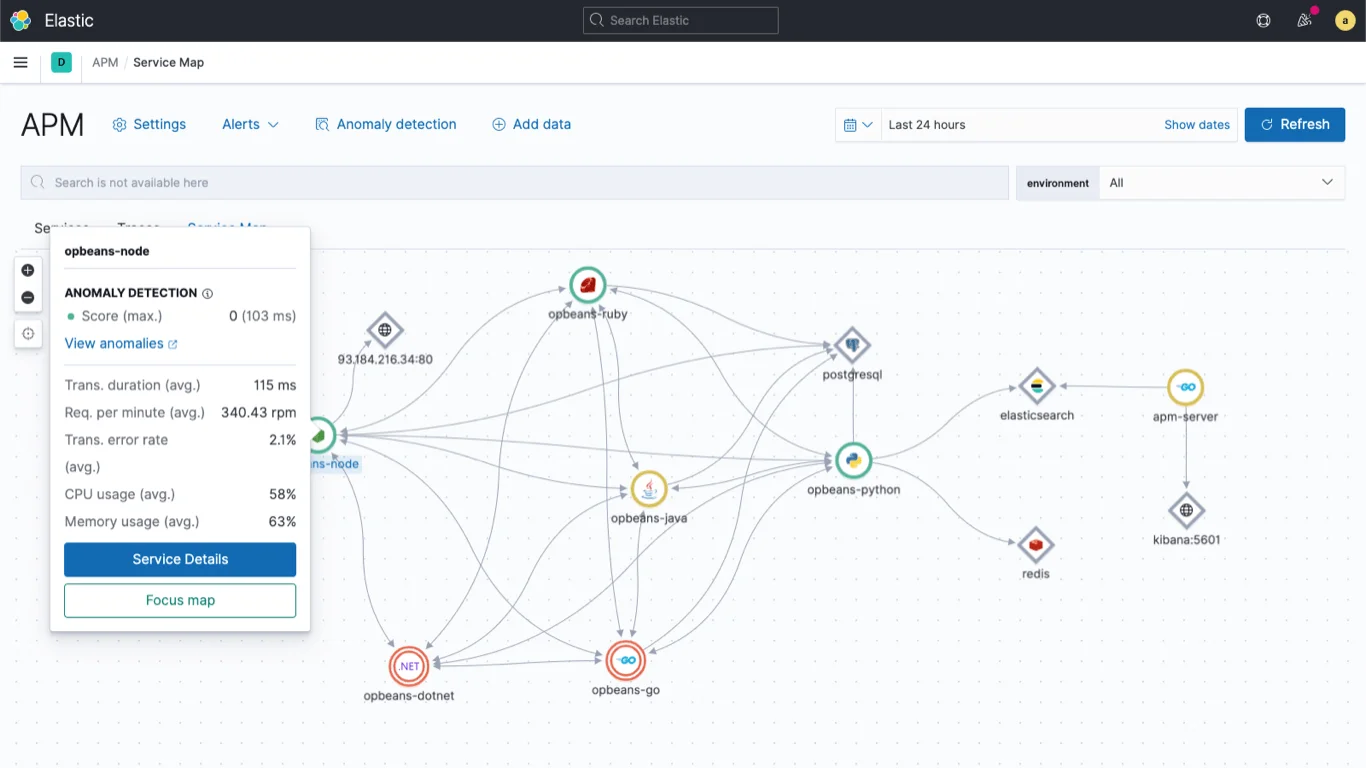
Elastic APM is a tool in the Elastic Stack for monitoring user experience through real user monitoring (RUM). It tracks page load times, interaction delays, and error rates, helping teams identify and fix performance issues.
Elastic APM uses Google’s Core Web Vitals, covering loading performance, visual stability, and interactivity. This ensures high website performance, improving user satisfaction and search engine rankings. It also integrates with Elastic’s observability suite to correlate logs, metrics, and traces, giving a full view of application performance and user experience.
Key Elastic APM features include:
- Distributed tracing
- Automatic instrumentation
- Error tracking
- Service maps
- Customizable dashboards
- Transaction sampling
- Real-time monitoring
- Environment-specific metrics such as development, staging, and production
10. Zabbix
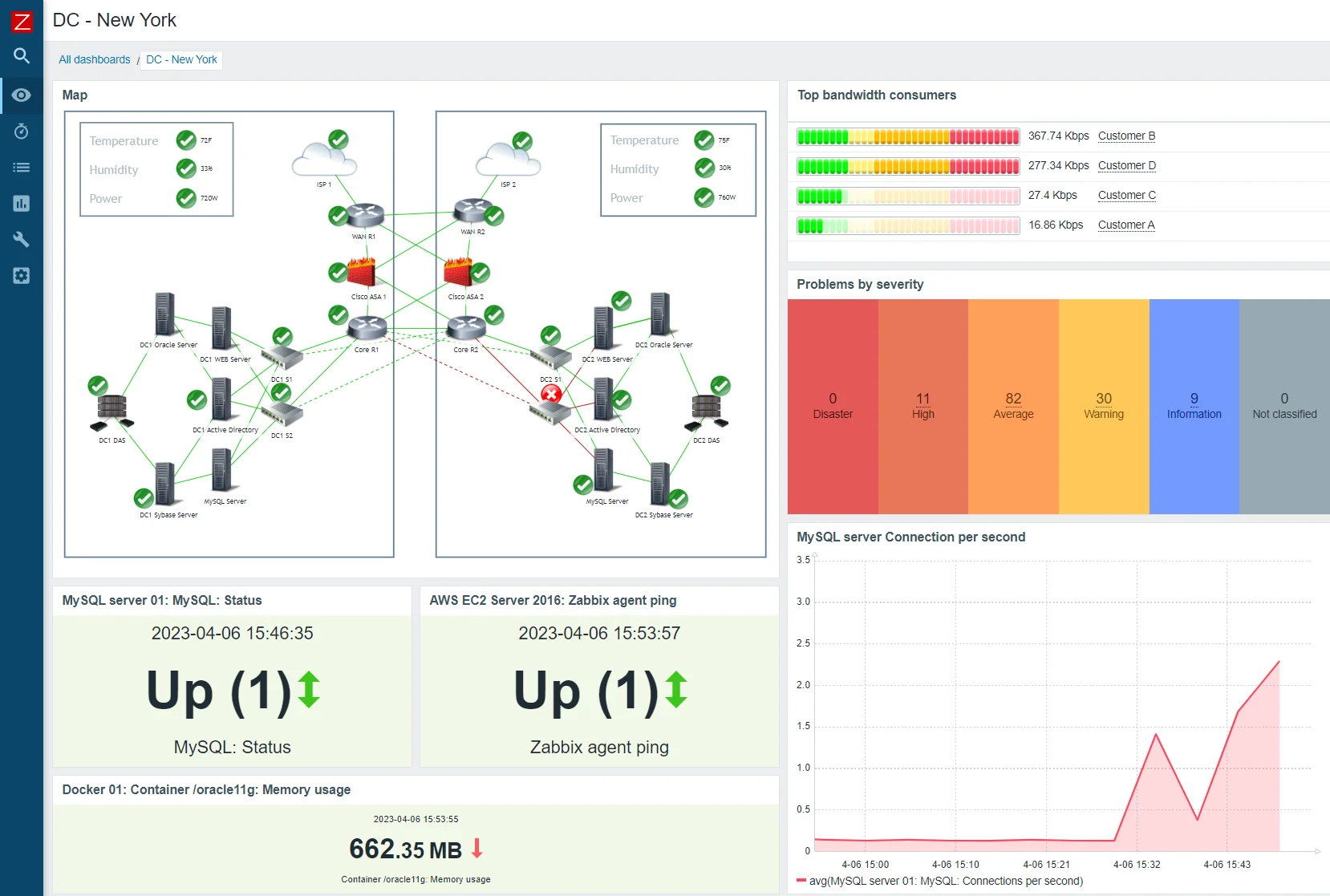
Zabbix uses agents to collect metrics from servers, network devices, and applications. These agents measure performance, availability, and configuration while using minimal resources. Zabbix also supports agentless monitoring via SNMP, IPMI, and HTTP protocols. This allows it to monitor a wide range of devices and applications. It automates the discovery of network devices and resources, making it easy to scale and manage large infrastructures.
Key Zabbix features include:
- Automated discovery
- Data visualization
- High availability
- SSL-protected user access for robust security
- Scalability
- Supports API for custom integrations and automation
Cloud Provider Native Monitoring
Every major cloud provider includes built-in monitoring tools that offer deep integration with their respective services — often at no additional cost for basic usage. For teams running workloads primarily on a single cloud provider, these native tools provide the easiest path to visibility with zero setup friction. They also serve as foundational data sources that feed into third-party APM platforms.
11. Amazon CloudWatch
Amazon CloudWatch is AWS’s native monitoring and observability service, collecting metrics, logs, and events from over 70 AWS services automatically. It provides dashboards, alarms, and anomaly detection out of the box. For application monitoring, CloudWatch Application Insights automatically detects common application problems, surfaces correlated findings, and provides guided remediation steps. Its ServiceLens feature integrates traces, metrics, and logs for end-to-end observability of distributed applications running on AWS.
Key CloudWatch features include:
- Automatic metric collection for all AWS services
- Custom metrics and high-resolution alarms
- CloudWatch Logs Insights for fast log querying
- Anomaly detection powered by machine learning
- ServiceLens for distributed tracing integration
- Synthetics for canary monitoring of endpoints
12. Azure Monitor
Azure Monitor is Microsoft’s comprehensive monitoring solution for Azure-hosted applications and infrastructure. It collects and analyzes telemetry from cloud and on-premises environments, providing full-stack observability through Application Insights (for APM), Log Analytics (for log queries), and Azure Metrics. Its integration with Azure DevOps and Microsoft Teams makes it particularly effective for organizations already embedded in the Microsoft ecosystem.
Key Azure Monitor features include:
- Application Insights for APM with auto-instrumentation
- Log Analytics with Kusto Query Language (KQL)
- Workbooks for interactive visual reports
- Smart detection and proactive diagnostics
- Integration with Azure Advisor for optimization recommendations
- Supports hybrid and multi-cloud via Azure Arc
13. Google Cloud Monitoring
Google Cloud Monitoring (part of Google Cloud Operations, formerly Stackdriver) provides visibility into the performance, uptime, and health of applications running on Google Cloud. It collects metrics, events, and metadata from GCP services, AWS, and on-premises infrastructure. Its tight integration with Google Kubernetes Engine (GKE) and Cloud Run makes it the natural choice for teams running containerized workloads on GCP.
Key Google Cloud Monitoring features include:
- Pre-configured dashboards for GCP services
- Uptime checks and alerting policies
- Service Level Objective (SLO) monitoring
- Cloud Trace for distributed tracing
- Cloud Logging integration
- Multi-cloud support via BindPlane
Specialized Observability And Error Tracking
Not every monitoring need requires a full-stack APM platform. These specialized tools focus on specific aspects of observability — deep debugging in production, error tracking, log analytics, or real-user experience monitoring — and often complement broader platforms by providing depth where general-purpose tools offer breadth.
14. Honeycomb
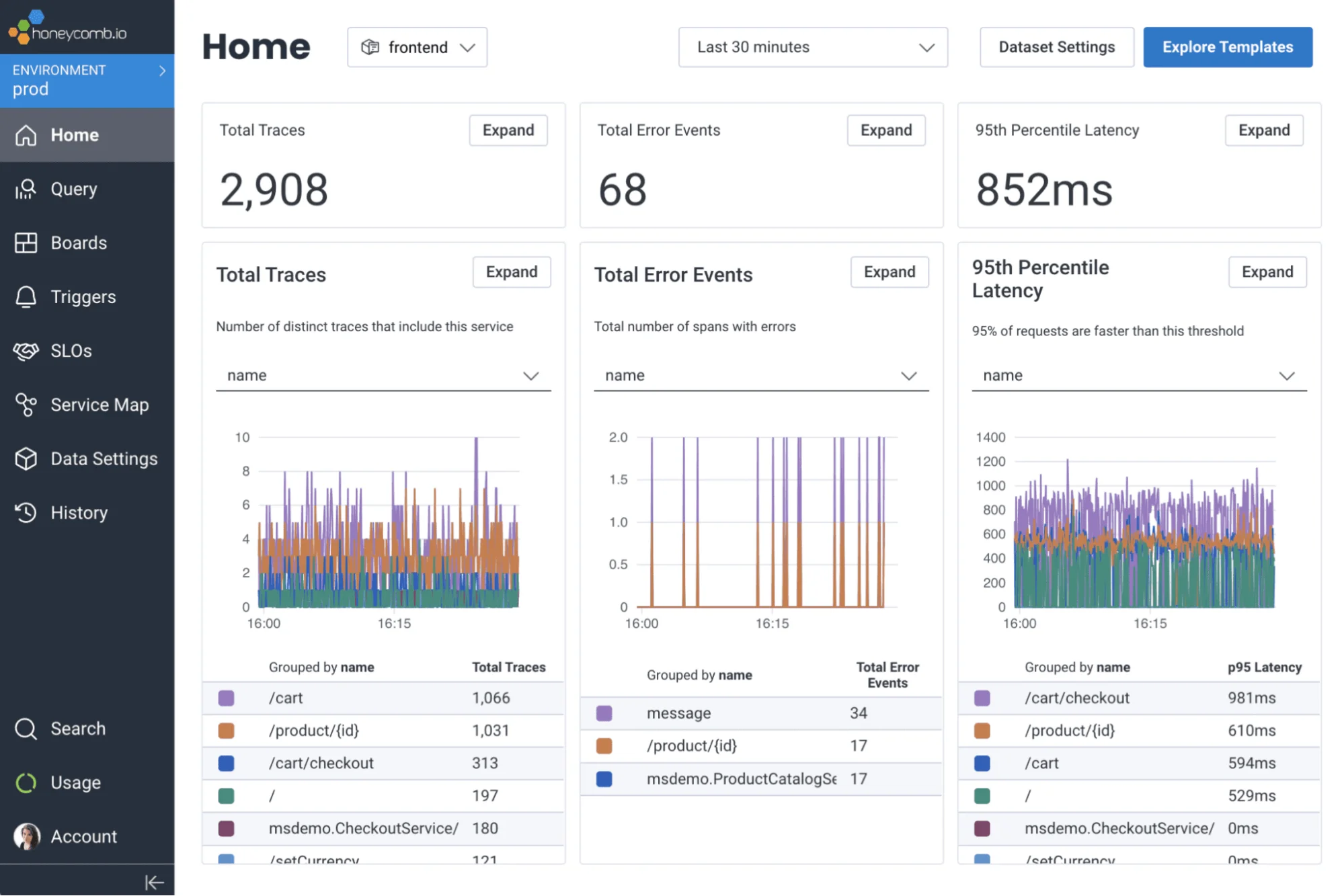
Honeycomb is an observability tool built for debugging complex production systems. It features detailed insights into distributed architectures, enabling fast incident resolution. Honeycomb integrates with CI/CD pipelines and supports automated tracing, real-time monitoring, and performance optimization.
Key Honeycomb features include:
- Real-time complex dependency mapping
- Distributed tracing
- Service Level Objectives (SLOs)
- Team collaboration tools
- OpenTelemetry integration
- Automated incident detection
- Timeline markers
15. Sentry

Sentry collects real-time data on application performance, identifying slowdowns and bottlenecks. It highlights transaction traces to reveal the path and time taken for operations. Sentry also tracks errors and exceptions with detailed reports, including stack traces and context, to understand root causes. By linking performance issues and errors to specific releases, Sentry enables targeted improvements.
Key Sentry features include:
- Error tracking with full stack traces
- Customizable alerts
- Release tracking
- Issue management and assignment
16. Chronosphere
Chronosphere is a cloud-native observability platform purpose-built for high-scale environments generating massive volumes of telemetry data. Founded by former Uber engineers who built M3 (Uber’s open-source metrics platform), Chronosphere focuses on controlling observability data growth and costs — a critical concern as monitoring data volumes expand exponentially. Its data shaping and control plane features let engineering teams set policies that manage which data is stored, aggregated, or dropped.
Key Chronosphere features include:
- Control plane for managing observability data volume and costs
- Built on open-source M3 and compatible with Prometheus
- Data shaping to aggregate or drop low-value metrics
- High-cardinality metric support
- OpenTelemetry native
- Team-based dashboards and access controls
17. Logz.io

Logz.io, with its ELK Stack and advanced analytics, provides a managed observability platform combining log analytics, infrastructure monitoring, and distributed tracing. It uses rules, threat intelligence, and anomaly detection to find and address issues. Logz.io handles logs from web servers, databases, and firewalls, automatically parsing and enriching them for accurate analysis.
Key Logz.io features include:
- Service performance monitoring with aggregated R.E.D. metrics
- Real user monitoring
- Synthetic monitoring
- Cross-platform alerting for automatic issue notifications
- Distributed tracing
- Service map visualization to show data flow and dependencies
- Anomaly detection
- Data Optimization Hub to manage and reduce unnecessary data
18. Raygun
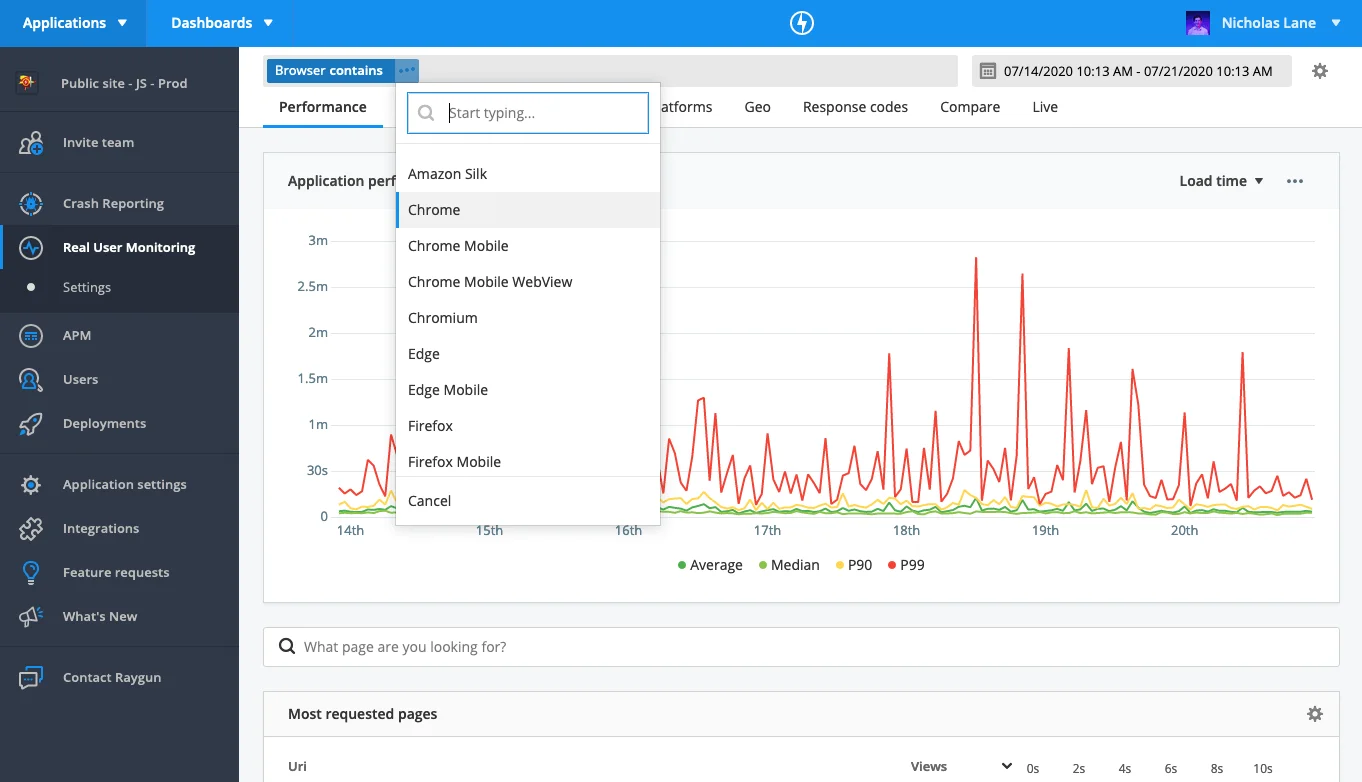
Raygun’s Real User Monitoring (RUM) gives insights into user interactions with web and mobile applications. It tracks performance metrics like page load times, session details, and errors in real-time. By capturing these metrics, Raygun identifies performance issues affecting the user experience. RUM shows a detailed breakdown of load times, helping developers find and address slowdowns quickly. This monitoring resolves issues before they affect users, boosting satisfaction and performance.
Key Raygun features include:
- Tracks individual user experiences and errors
- Detailed error reports, including stack traces, environment data, and more
- Integrates with popular tools such as Slack, GitHub, JIRA, and more
- Monitors the impact of new deployments on application stability
- Configurable alerts
- Robust API for custom integrations
The above tools enable organizations to gain deep visibility into the performance of their applications. However, there is a major concern when it comes to application monitoring: cost management.
How To Manage Application Monitoring Costs With CloudZero
Application monitoring generates vast amounts of data, leading to higher operational costs. The tools collect metrics, logs, and traces, requiring significant storage and processing power, especially in dynamic cloud environments. High scalability and sophisticated analytics further increase costs.
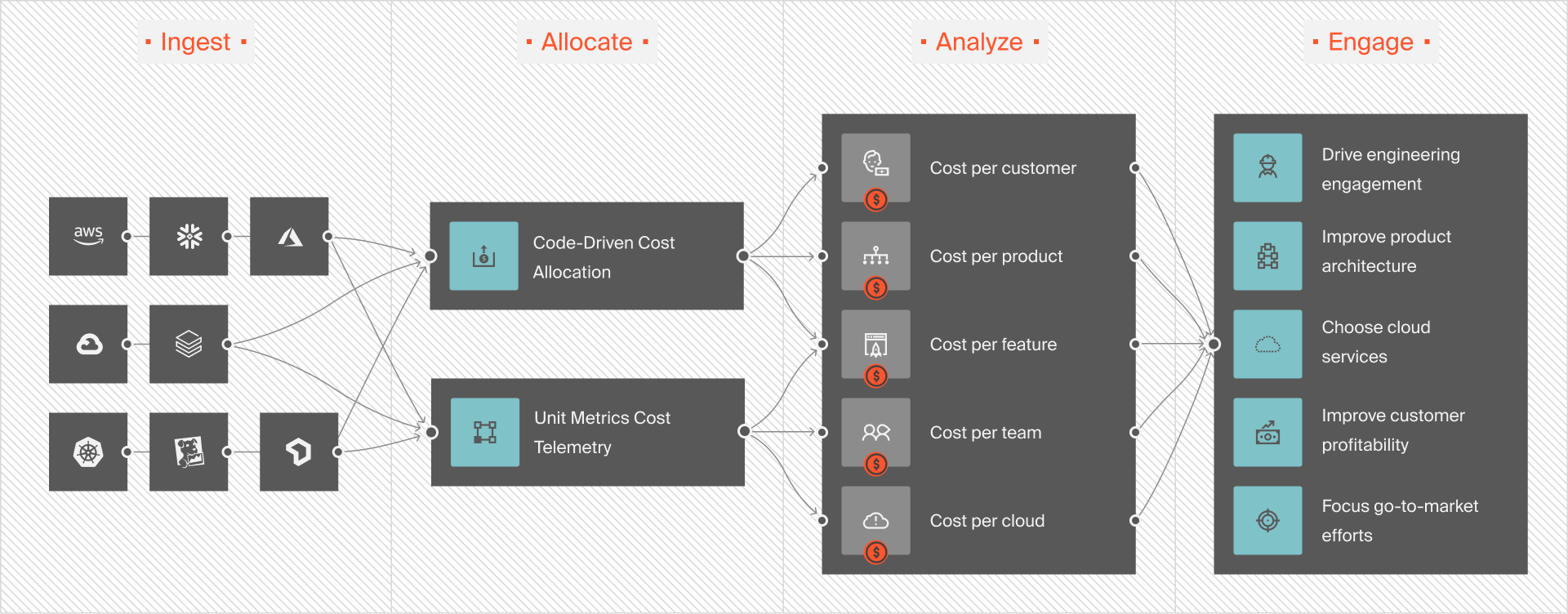
CloudZero can help with its robust cost management solutions. The platform helps businesses understand, control, and optimize their spending on application monitoring by:
Integration with application tools
CloudZero integrates with Datadog, New Relic, and more to allow organizations to correlate performance data with cost data.
For example, CloudZero’s integration with Datadog offers detailed cost allocation and analysis. It allows users to visualize and explore their Datadog spend without needing tags. It also allocates costs using metrics such as cost per feature, product, microservice, team, and more. These enable granular cost control and optimization of running application monitoring.
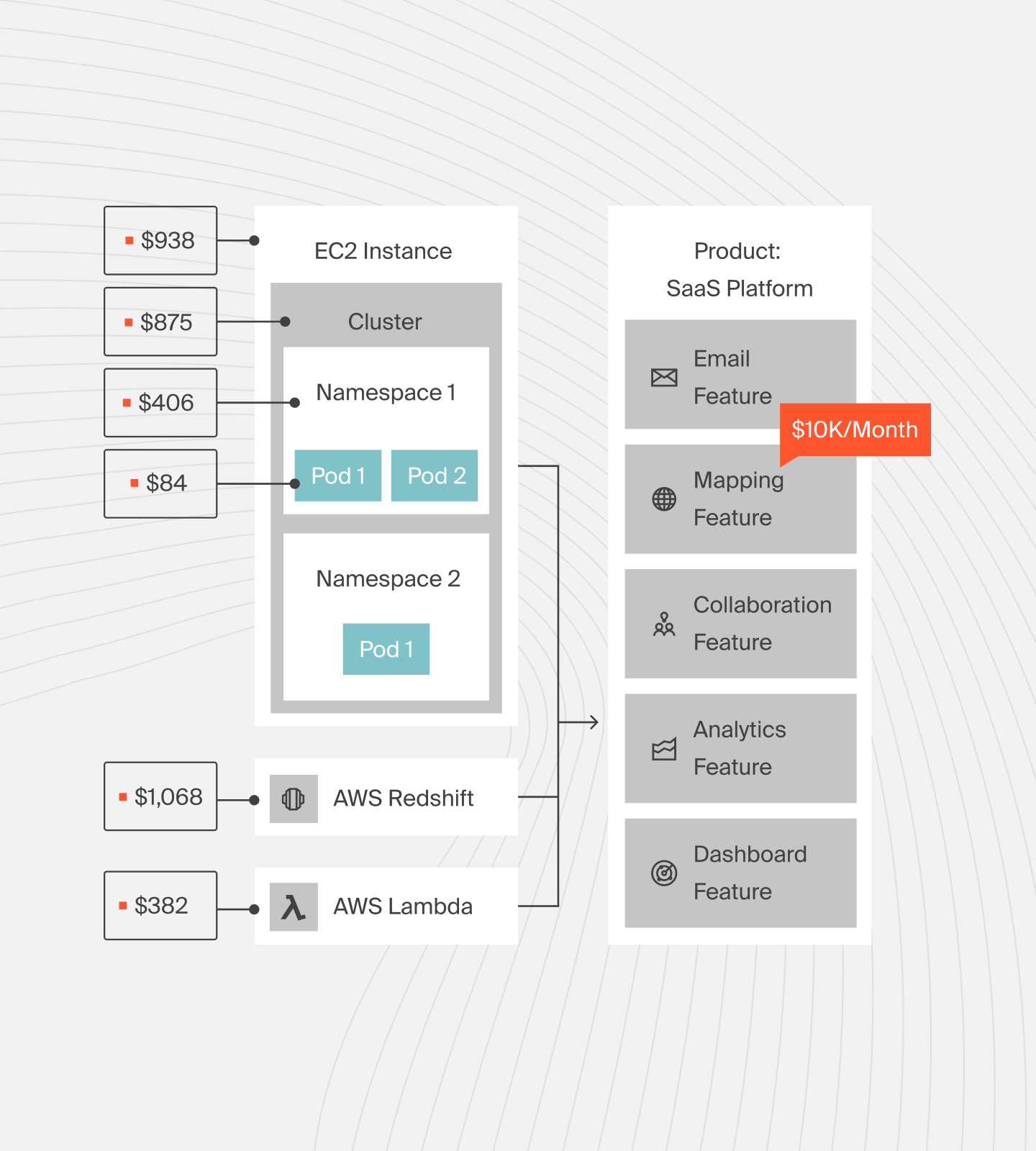
Kubernetes cost visibility
Monitoring Kubernetes (K8s) involves tracking the performance of nodes, pods, and containers. Platforms like Prometheus, Datadog, and New Relic support Kubernetes monitoring by providing metrics, logs, and performance insights.
CloudZero integrates with Kubernetes to manage costs by providing visibility into spending. It breaks down costs by namespaces, pods, and clusters, integrating this data with overall cloud costs. Additionally, it offers analytics to visualize Kubernetes spending in relation to business objectives, aiding in better financial planning and resource management.
CloudZero also:
- Offers real-time visibility into cloud spending to detect and address cost anomalies promptly
- Sends automated alerts for unusual spending patterns to prevent budget overruns
- Analyzes historical spending data to forecast future costs and optimize budget planning
- Recommends optimization strategies for better resource use and cost savings
- Integrates with major cloud providers — AWS, Azure, and Google Cloud — for comprehensive cost tracking
- Implements cost management policies to ensure compliance and control over cloud spending
Schedule a demo to see CloudZero in action.











