
Not long ago, our co-founder and CTO, Erik Peterson, shared some insights on AI spending. He shared how AI costs currently fall under the write-off-friendly world of R&D. He also acknowledged why DevOps teams might feel it’s too early to start optimizing AI costs.
As the saying goes, “Premature optimization is the root of all evil.”
But after more than a decade of software development, Erik knows that eventually, research, experimentation, and big ideas need to deliver real returns.
Over the next few minutes, we’ll share actionable AI cost optimization strategies you can apply right away. The goal? Prevent overspending without compromising innovation.
How AI Influences Cloud Spending Today
To start, AI workloads require significantly more compute power, storage, and data analytics than traditional cloud operations. This is primarily due to their need for parallel processing and large-scale data handling.
Continuous vs. fluctuating resource usage
Traditional cloud workloads often experience spiky, fluctuating demand (e.g., during peak traffic), allowing for dynamic scaling and cost optimization.
In contrast, AI workloads — especially for training large models — require continuous, high-power compute resources for extended periods, making cost control more challenging.
Expensive, specialized hardware
AI workloads depend heavily on GPUs, TPUs, and other accelerators designed for parallel processing and complex computations. These are far more expensive than the standard CPUs used in traditional cloud applications.
Massive data storage and processing
AI applications require enormous datasets for training and inference, which demand high-performance storage and efficient data pipelines. Both add to cloud costs.
Limited elastic scaling
While traditional cloud workloads can scale elastically, AI workloads often require pre-planned capacity due to their high and consistent resource consumption. This frequently leads to overprovisioning, a surefire way to Ferrari through your cloud budget.
Overall, these differences make AI workloads more demanding in terms of infrastructure and cost management.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
Measuring The ROI Of AI Systems And Projects
But before your AI project costs spill over into OpEx and impact profitability and scalability, you can start measuring them early. Then you can assess whether your AI investments make financial sense over time and adjust accordingly.
CloudZero’s CTO sums it up squarely:
“I’m not suggesting that dev teams start optimizing their AI applications right now. But I am suggesting they get out in front of the cost nightmare that tends to follow periods of high innovation.”
That’s to say, if you’re investing heavily in AI, you can be proactive about cost control — before it becomes a severe ache for your margins.
Related reads:
AI Cost Optimization: How To Reduce AI Expenses While Maximizing Efficiency
Here are some key AI cost optimization strategies for reducing cloud AI spend while preserving engineering velocity. Plus, we’ll look at real-world examples of companies successfully using these techniques to cut AI costs.
1. Use Spot instances for AI workloads
Spot instances from AWS, Azure, and Google Cloud offer access to unused compute capacity at discounts of up to 90% compared to on-demand pricing. They’re suitable for non-critical, interruptible workloads like AI model training and batch processing.
For example, training a large language model (LLM) on spot instances can save you thousands, so long as the workload can tolerate occasional interruptions.
Uber’s AI platform, Michelangelo, uses AWS Spot Instances to train machine learning models efficiently while keeping costs low. Similarly, Anthropic takes advantage of AWS Spot Instances when GPU prices drop.
A smart workaround is checkpointing, where training jobs periodically save progress to avoid restarting from scratch.
Better still, consider using tools like Xosphere. It dynamically switches your workloads between spot and on-demand instances. This ensures you maximize savings without risking downtime.
2. Take advantage of cloud FinOps for AI spending
AI workloads are expensive due to unpredictable scaling, GPU-intensive requirements, and data transfer costs. Cloud FinOps — a key discipline in AI FinOps — provides a framework to monitor, allocate, and optimize your AI spend proactively. This includes:
- Tagging resources by project, team, or workload to track cost attribution.
- Setting up real-time anomaly detection to catch unexpected spikes in AI model inference costs.
- Rightsizing compute resources to ensure your team uses the appropriate instance types, say, moving from A100 GPUs to T4 GPUs when feasible. Use a tool like CloudZero Advisor to choose the right resource configurations based on your workload, budget, and service type, balancing optimal performance with cost efficiency.
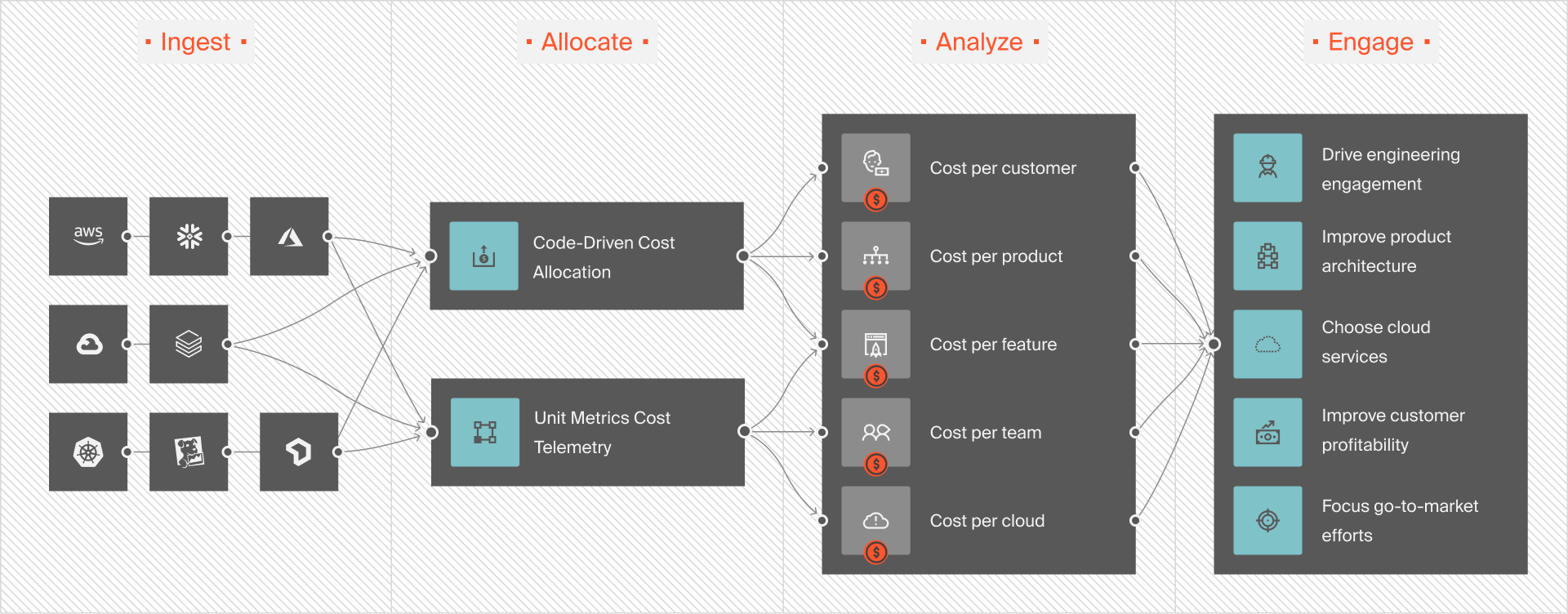
The thing is, not all platforms offer this level of exact cloud cost intelligence. However, a robust AI cost optimization platform like CloudZero goes even deeper. For example, it offers immediately actionable insights such as cost per AI model, SDLC stage, dev team, and more.
Want to see this in action?  to dive in and experience CloudZero firsthand.
to dive in and experience CloudZero firsthand.
3. Improve AI model efficiency
Running large AI models on cloud GPUs can be expensive, but companies like OpenAI use model compression techniques to cut costs without sacrificing performance. Some of the most effective methods include:
- Knowledge distillation: A smaller model learns from a larger one, reducing GPU usage while maintaining accuracy.
- Quantization: Reducing model precision (e.g., from 32-bit to 8-bit) enables models to run efficiently on lower-cost hardware.
- Model pruning: Removing unnecessary parameters lowers inference costs without impacting results.
These techniques can help you streamline AI models, making them more cost-effective without compromising their capabilities. For example, a distilled version of a large transformer-based model can achieve similar accuracy with significantly fewer computational resources.
Also, consider using pre-trained models from platforms like Google’s Vertex AI Model Garden to cut costs further. This minimizes the need to train models from scratch.
4. Automate resource management
AI workloads fluctuate. Demand peaks during training and drops at other times. Without automation, idle cloud resources can rack up unnecessary costs. Fortunately, most major cloud providers offer automation tools at no extra cost to prevent this.
Here’s how.
- Autoscaling dynamically provisions resources for AI inference workloads, ensuring the infrastructure scales up or down as needed. Use tools like Kubernetes or AWS Auto Scaling to streamline this process for AI workloads.
- Automated decommissioning shuts down idle instances, avoiding wasted spend.
A great example of this in action is Spotify. The streaming giant uses auto-scaling for its AI-driven music recommendations, ensuring GPU resources are only active when needed
5. Negotiate volume discounts with cloud providers
Cloud providers offer Committed Use Discounts (CUDs) and Savings Plans that can help you slash AI compute costs by 40%–60%, especially for predictable workloads.
For larger organizations, custom pricing is also an option. Consider negotiating volume-based discounts or committing to Reserved Instances (RIs) to lock in lower rates.
Committing to a one or three-year RI plan for GPUs or TPUs used in AI projects can yield significant savings compared to pay-as-you-go pricing.
Even tech giants take advantage of these deals. Meta (Facebook) secured custom GPU pricing with AWS for its large-scale AI research projects, cutting per-hour compute costs.
But you don’t need to be a massive enterprise to negotiate better rates. Cloud providers often consider factors like growth projections, market share, and future spending when offering discounts. See if you can leverage these to secure more favorable terms.
6. Optimize storage and data transfers
AI projects generate massive datasets. Storing and moving this data inefficiently can drive up your cloud bill.
Here’s how to keep them in check:
- Use tiered storage: Store frequently accessed data in hot storage while archiving older data in warm or cold storage to reduce costs.
- Minimize egress costs: Keep AI processing within the same cloud region to avoid expensive inter-region transfer fees.
- Compress your data: Use efficient formats like Parquet instead of CSV to reduce storage and I/O costs.
Another idea here is to use content delivery networks (CDNs) or caching mechanisms for inference data to significantly cut AI-related data transfer costs.
7. Understand TCO for AI projects
Break down the Total Cost of Ownership of your AI projects — including GPU costs, inference, storage, and operational support — to surface hidden cost drivers. This can help you pinpoint cost drivers and optimization opportunities.
Related read: Guide To Calculating TCO On AWS And Tools To Help
Here’s what we mean:
- Training: Switch to more cost-efficient GPU instances or use pre-trained models to reduce compute expenses. For early experiments, train on smaller datasets before scaling up.
- Inference: Balance latency and cost using smaller models or dedicated inference accelerators. Deploy lightweight models for production to minimize resource consumption.
- Data storage and transfer: Watch out for cross-region transfer costs, an often “hidden” cost in the cloud.
Also, consolidate redundant datasets and enforce data governance policies to prevent unnecessary storage fees.
8. Look beyond NVIDIA GPUs
Most AI workloads default to NVIDIA GPUs. However, alternative hardware can significantly reduce costs without sacrificing performance.
Here are some options to consider:
- AWS Inferentia and Trainium: Expect AWS-designed chips that cut inference and training costs by up to 50% compared to GPUs.
- Google TPUs (Tensor Processing Units): These are purpose-built for AI workloads and offer superior performance and lower operational costs than GPUs for certain tasks.
- AMD and Intel AI Chips: Options like AMD’s MI300 and Intel’s Gaudi series deliver lower pricing and improved energy efficiency, making them a compelling alternative.
Google is so confident in its TPU ecosystem that it runs its own AI workloads entirely on TPUs. It’s a move that likely saves the Alphabet company billions annually compared to renting GPUs.
9. Offload AI inference to edge computing
Instead of relying entirely on the cloud for AI inference, consider offloading some workloads to edge devices.
For example, AI models can run directly on user devices (like Apple’s on-device Siri processing) or edge servers closer to users.
This approach can reduce data transfer and cloud inference costs, especially for latency-sensitive applications.
10. Take advantage of open-source AI models instead of proprietary APIs
Many companies pay steep fees for API-based AI services like OpenAI’s GPT-4, Google’s Gemini, or AWS Bedrock. A cost-effective alternative? Switch to open-source LLMs and host them in-house or on a private cloud.
Here’s why it makes sense:
- Free, high-quality models: Open-source options like Llama 3 (Meta) and Mistral 7B offer state-of-the-art performance. You can also fine-tune them at a fraction of the cost.
- No ongoing API fees: Running AI on-premises or in a private cloud eliminates recurring costs from third-party AI services.
- More control and customizability: You are free to fine-tune models to fit your specific needs without vendor limitations.
Companies like Cohere and Stability AI use open-source models to power their products. And this helps them minimize reliance on expensive third-party APIs.
11. Dynamically do GPU rentals and cloud reselling
GPU pricing fluctuates based on supply and demand, leading to potential inefficiencies. Instead, you can rent out unused GPUs on platforms like GPUX and Akash Network and turn it into revenue. Before committing, use cloud cost optimization tools to benchmark whether renting vs. owning makes financial sense.
Additionally, consider using GPU aggregators. Services like RunPod and Lambda Labs provide real-time pricing comparisons across multiple cloud providers. Explore them to get the best deals.
A great example here is Stability AI. It dynamically rents GPUs from multiple providers to secure the best pricing at any given time.
12. Data-driven AI training with active learning
AI training is expensive partly because models often process redundant or low-value data. What’s a smarter approach?
Active learning.
This involves prioritizing only the most informative data samples (reducing computational costs without sacrificing accuracy).
You get smaller, more efficient datasets this way. This means filtering out unnecessary data to shrink the training size, which, in turn, cuts compute costs.
You can also speed up model development by skipping low-value computations.
Yes, active learning requires extra effort to curate datasets. But the potential savings can make it well worth your time.
13. Use Function-as-a-Service (FaaS) for AI preprocessing
Preprocessing data before AI inference is often a hidden cost. So instead of running full-fledged VMs, why not try these:
- Use AWS Lambda, Google Cloud Functions, or Azure Functions to preprocess data on-demand.
- Run lightweight AI tasks serverlessly, paying only for execution time.
Airbnb does this. The short-term rental service processes image metadata using FaaS before sending it to AI models. And this helps its team reduce always-on compute costs.
14. Train your models in low-cost cloud regions
You already knew that cloud pricing varies significantly by region. So, see if you can deploy workloads in lower-cost regions while balancing performance and latency.
For example, AWS Mumbai and Google Cloud São Paulo offer significantly cheaper AI compute than US-based regions.
Also consider cloud region arbitrage to optimize costs while maintaining acceptable network latency.
A good real-world example here is ByteDance. It trains its AI models in Singapore instead of the US. This helps the team shave costs without sacrificing performance.
15. Enable AI model caching for repeat queries
Cache AI responses for frequently asked queries, such as chatbot replies or search results, to cut unnecessary processing.
Use response caching, like ChatGPT APIs, which store frequently asked responses, reducing real-time compute expenses.
And you can also take advantage of vector databases. Tools like FAISS and Pinecone store and retrieve embeddings efficiently, minimizing redundant computations. Pair this with cloud cost management tools that track inference spend in real time.
16. Understand who, what, and why your AI costs are changing
We’ve touched on this before, but here’s the real issue: It’s one thing to see a lump-sum cloud bill. It’s another to understand exactly how different teams, products, and processes drive that cost.
This lack of visibility can be paralyzing.
- Cut costs blindly, and you risk stunting AI innovation.
- Let things run unchecked, and you could burn through your quarterly cloud budget faster than an NFL game.
The Solution: Balance AI Innovation With Cost Efficiency
And that’s where CloudZero stands out. It gives you granular cost insights like:
- Cost per model, feature, service, SDLC stage, and project, so you know exactly where to cut waste without sacrificing performance, user experience, or engineering velocity.
- Actionable investment insights, helping you pinpoint where to spend smarter for the highest ROI on AI.
AI-first organizations like Rapid7 and Helm.ai already trust CloudZero for this and more. Now, you can too. Risk-free. and start optimizing your AI costs without starving innovation.


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.


